Top 10 Apache projects in 2021, from Superset, to NuttX and Pulsar
2,493 ASF committers and 9,604 authors changed 515 million lines of code in 2021. Here's what was most active.
2,493 ASF committers and 9,604 authors changed 515 million lines of code in 2021. Here's what was most active.

If you’ve moved up the food chain as a digital leader, it can be hard to keep abreast of what’s enthusing other technologists until someone starts chewing your ear about serverless* or NFTs**. A peak at some of the most active open-source projects is a good way to see what’s occupying some of the world’s developers; many of the most active projects were also spawned at digital-native companies with a track record of innovation.
Last year the Apache Software Foundation (ASF) – the custodian of $22 billion-worth of open-source software -- saw 2,493 committers and 9,604 authors change 515 million lines of code. While that vibrant activity was widely spread across 351 projects, a smaller handful drew the most commit activity (code contributions).
Here are the 10 top Apache projects in 2021 by commit activity, from Superset to NuttX and beyond.
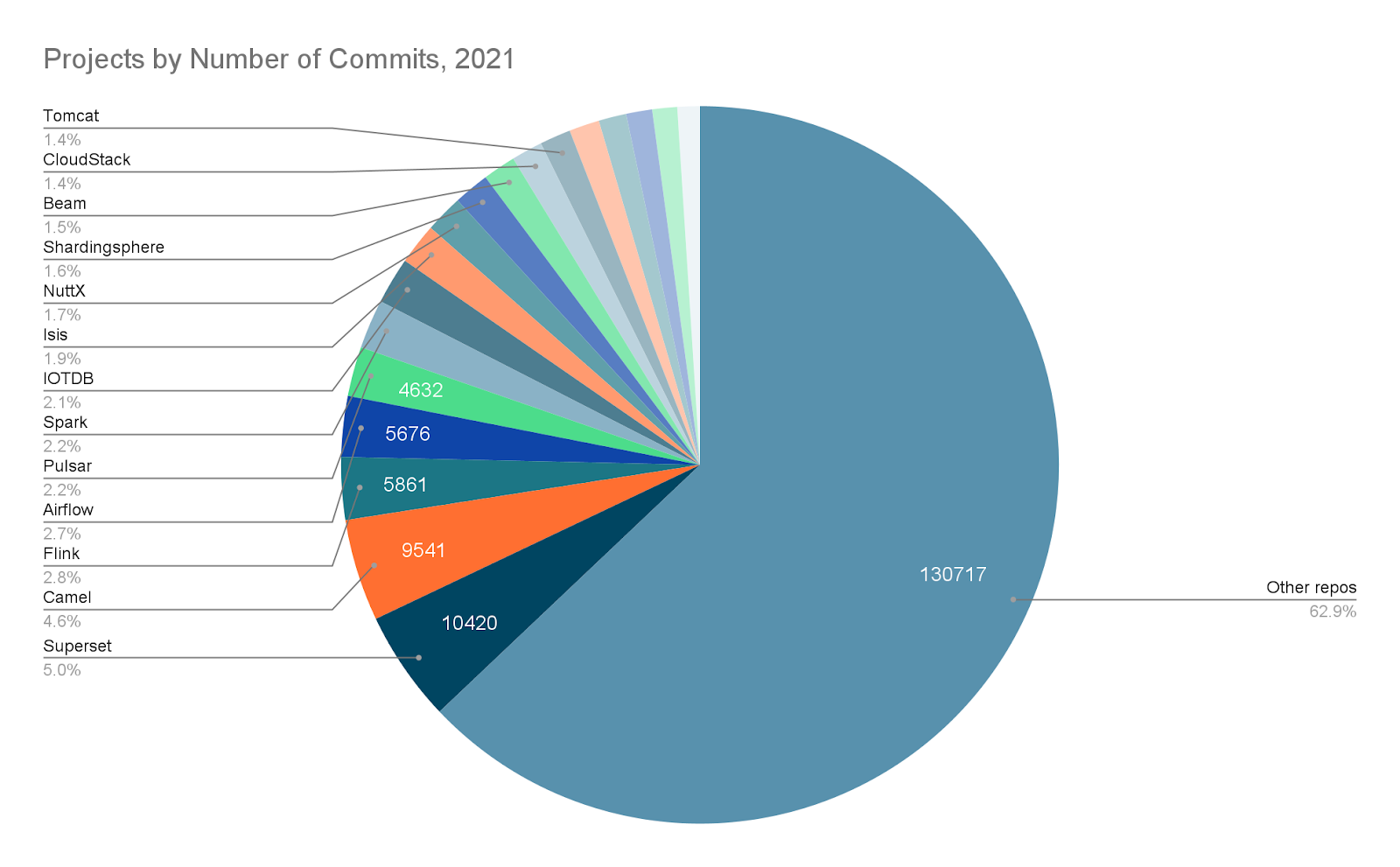

Apache Superset was the only individual project to see over 10,000 commits – and has attracted nearly 43,000 stars on GitHub (and 8,400 forks). The open-source data visualisation and data exploration platform is enterprise-ready and can, its advocates claim, “replace or augment proprietary business intelligence tools.”
Superset was born at Airbnb (itself a fantastic incubator and supporter of open source projects).
It provides a no-code interface for building charts; an API for programmatic customisation; a web-based SQL editor for advanced querying; a lightweight semantic layer for defining custom metrics; out-of-the-box support for MySQL, PostgreSQL and SQLite (“pretty much any databases that have a SQLAlchemy integration should work perfectly fine as a data source”); a range of visual templates from bar charts to geospatial visualisations; a cloud-native architecture and highly extensible security and authentication options for administrators.
Apache Superset is in use at a wide range of companies. According to one of its early committers, Bogdan Kyryliuk, these include Airbnb, American Express, Lyft, Nielsen, Rakuten Viki, Twitter, and Udemy.
It’s also used as the main data exploration tool at Dropbox, which consolidated 10 tools to Superset.
Are you a Superset user? What do you like/dislike about it. Drop us a line.
Apache Camel saw over 9,500 commits in 2021 – and has attracted 4,100+ stars and 4,400+ forks on GitHub.
Data tools rule the roost at the moment and Camel is no exception. Apache Camel is an open-source “micro integration” framework for users of distributed systems. As middleware, it lets users integrate different message systems consuming or producing data, improving the management and connectivity of microservices.
(That’s a growing challenge for anyone managing most modern applications, with developers often having to deal with asynchrony, partial failures, and data models that just do not want to coexist easily…)
Enterprise Integration Patterns (EIP) – a way to describe, document and implement these complex integration problems – has become increasingly widely adopted. Apache Camel, in brief, is a way to implement EIP. As the project describes it: “Apache Camel uses URIs [resource identifiers] to work directly with any kind of transport or messaging model such as HTTP, ActiveMQ, JMS, JBI, SCA, MINA or CXF, as well as pluggable Components and Data Format options. Apache Camel is a small library with minimal dependencies for easy embedding in any Java application. Apache Camel lets you work with the same API regardless which kind of transport is used — so learn the API once and you can interact with all the Components provided out-of-box.”
Are you a Camel user? What do you like/dislike about this top Apache project in 2021? Drop us a line.
Apache Flink saw over 5,800 commits in 2021 – and has attracted 17,000+ stars and 10,000_ forks on GitHub.
An open-source stream processing framework, Apache Flink supports batch processing and data streaming. Briefly, it can reliably process a tonne of data in real time, at pace; something that has become ever more important as enterprises look to react to data feeds as fast as possible (whether that’s Internet of Things data, user journey data/click streams for complex retail applications, or any other use case…)
Use cases are diverse and range from event-driven microservices, to data pipelines for ETL: a fork of Flink is used by Alibaba to optimise search rankings in real time and by Capital one for real-time activity monitoring; Ericsson meanwhile used Flink to build a real-time anomaly detector for large infrastructures.
Flink can perform stateful or stateless computations over data and has a lively community. It can handle up to 1.7 billion messages per second, according to users at Alibaba, which has a good use case example here.
Are you a Flink user? What do you like/dislike about this top Apache project in 2021? Drop us a line.

Apache Airflow saw over 5,600 commits in 2021 – and has attracted 24,000+ stars and 9,800+ forks on GitHub.
Another project born at Airbnb, Airflow is a platform to programmatically author, schedule, and monitor data workflows and is often used to orchestrate disparate tools into a single place – something which might (for AWS users) otherwise mean manually managing schedules via AWS Datapipelines, Lambdas, and ECS Tasks.
Much-used by data engineers (the majority of whom, for what it’s worth, are running PostgreSQL as their “meta-database”, with growing numbers using some kind of Kubernetes deployment), it lets users automate processes in Python and SQL and has a rich web UI to visualise, monitor and fix issues; it also boasts a comprehensive set of integrations with popular cloud services, from Azure Container Instances, AWS Glue, GCP Text-to-Speech and beyond. One of the best guides for new users is by data scientist Rebecca Vickery and can be read here. You can also refer to this Stack Overflow thread for more details on deployment.
Are you an Airflow user? What do you like/dislike about this top Apache project in 2021? Drop us a line.

Apache Pulsar saw over 4,600 commits in 2021 – and has attracted 10,200+ stars and 2,600+ forks on GitHub.
Apache Pulsar’s got pretty hot. We’ve written about it before here and here. A publish-subscribe (“pub-sub”) toolkit, it underpins messaging for event-driven systems and/or streaming analytics; it can also be used to decouple applications to boost performance, reliability and scalability. Similar though that may sound to Apache Kafka, there are pronounced differencesr, including how Pulsar separates compute and storage.
Pulsar, for example, delegates persistence to another system called Apache BookKeeper (a dedicated separate low-latency storage service designed for real-time workloads), and its “brokers” on the other hand are stateless — they are not responsible for storing messages on their local disk. (Pulsar brokers run an HTTP server with a REST interface for admin and topic lookup, and a dispatcher to handle all message transfers.)
As Jaroslaw Kijanowski, a developer at SoftwareMill notes tidily “[Statelessness] makes spinning up or tearing down brokers much less of a hassle… The separation between brokers and the storage allows to scale these two layers independently. If you require more disk space to store more or bigger messages, you scale only BookKeeper. If you have to serve more clients, just add more Pulsar brokers. With Kafka, adding a broker means extending the storage capacity as well as serving capabilities”.
Pulsar is at the heart of Yahoo! owner Verizon Media’s own architecture, where it handles hundreds of billions of data events each day. (Yahoo! developers described it in 2018 as “an integral part of our hybrid cloud strategy [that] enables us to stream data between our public and private clouds and allows data pipelines to connect across the clouds.”) It has also been deployed at COMCAST, Huawei, Splunk, and beyond.
Are you a Pulsar user? What do you like/dislike about this top Apache project in 2021? Drop us a line
Few Apache projects are as well established and indeed well adopted as Apache Spark. A multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters, Spark was created at UC Berkeley -- and as Databricks CEO Ali Ghodsi told The Stack’s founder back in 2018, back in 2009 its creators had struggled to even give it away. (“They said ‘this is academic mumbo-jumbo. We need enterprise software.’ We literally wanted to give it away and no one would take it.”)
It now powers petabytes of user data at eBay (log transaction aggregation and analytics), NASA (deep space network data) and beyond at thousands of companies. Per Databricks, Spark can be 100x faster than Hadoop for large scale data processing by exploiting in memory computing and other optimizations. Spark is also fast when data is stored on disk, and currently holds the world record for large-scale on-disk sorting.
It can run in Hadoop clusters through YARN or Spark's standalone mode, however, and it can process data in HDFS, HBase, Cassandra, Hive, and any Hadoop InputFormat – and as the ASF’s latest update shows, over a decade on continues to be one of the liveliest communities in the open source world.
Big Spark user? How do you rate Spark vs Pulsar? Drop us a line
The Apache Internet of Things Database (IOTDB), is an IoT-native database that was born at the School of Software (Tsinghua University). It has attracted 1,700+ stars on GitHub and 525 forks -- but seen some of the high levels of commit activity in 2021.
Users include the China Meteorological Administration and Lenovo.
Like many of the projects above, is one that can be deployed to tackle the problem of time-series data: the IoT requires efficient management of time-series data at both cloud and edge, with a need to handle throughput ingestion, low latency query and time series analysis.
It has deep integrations with Apache Hadoop, Spark, and Flink. (IoTDB provides connectors, such as hive-tsfile, spark-tsfile, and spark-iotdb, so Hive and Spark can directly access IoTDB data and files.)
It features Lightweight TsFile (a file format customized for storing time series data on IoT devices) management on edge nodes. Data on edge nodes can be written to the local TsFile, and basic query capabilities are provided. TsFile data can then be synchronized to the cloud.
As one of its architects puts it: “The design of IoTDB chooses to store the data in an open native time-series file format for both database access with Query/Storage Engine and Hadoop/Spark access against a single copy of the data. It also serves as a distributed time-series database, where data is partitioned by grouping of timeseries in Cluster Engine among different nodes while time-based data slicing is implemented on each node to improve the performances. IoTDB provides an SQL-like language, native API, and restful API to access data.”

Apache Isis is a framework for rapidly developing domain-driven apps in Java.
One committer goes as far as to call it a “platform for the domain” and Isis is all about Domain-driven design. As one recent Microsoft paper notes: “[DDD is about] organizing the code so it is aligned to the business problems, and using the same business terms (ubiquitous language). In addition, DDD approaches should be applied only if you are implementing complex microservices with significant business rules…”
Isis can be used for both microservice and monolithic architectures – and supports extremely fast prototyping and a short feedback cycle; handy for agile development. While not as big or widely forked as some of the projects above, its 45 contributors have been exceptionally active in the community and developed a hard-won reputation for great customer support among existing users.
Leading light and highly active contributor Dan Heywood got closest to lucidity when describing Apache Isis in an earlier blog as follows: “A problem all software projects encounter is making sure that code reflects the desired architectural principles/constraints. Many approaches have been tested, but the practical unification of architecture and code still eludes us. Apache Isis takes a different approach, forcibly separating architectural constructs from domain model, combining the two at runtime. It promises to free the developer from writing “boilerplate” and focus on the domain model instead” he noted in 2016.
Isis users, feel free to get in touch to explain to us how it works in language befitting small children.

Apache NuttX is real time embedded operating system (RTOS) that joined the Apache Incubator in 2019. (An RTOS can and has been crisply defined as "a piece of software designed to efficiently manage the time of a CPU"). It's attracted over 800 stars and 400 forks on GitHub.
There’s a lot of RTOS’s lurking on the interwebz. Many are largely dead, so it’s great to see one in the top 10 most-committed-to-ASF-projects in 2021.
“Think of it”, the NuttX folks says, as “a tiny Linux work-alike with a much reduced feature set.”
That’s underplaying it. NuttX is an unusual and feature-rich RTOS designed to run in tiny embedded environments. It’s hugely flexible -- you can run it on 8-bit, 16-bit, 32-bit or 64-bit microcontrollers; and, unusually, take your pick of RISC-V, Arm, ESP32, AVR, x86 – and “strives to achieve a high degree of standards compliance.”
It can built either as an open, flat embedded RTOS or as a separately built, secure, monolithic kernel with a system call interface. As one fan notes: “NuttX is a POSIX RTOS. You don’t need to learn a new API to program it. You can write an application in a POSIX Operating System like Linux or MacOS, validate it, and then compile it to run on NuttX. If you don't want to create an application from scratch, you can grab some small Linux libraries and perform some minor modifications to get them working on NuttX.”
It's been described as “natural option for complex IoT systems where sophisticated communications features are required” and is reportedly used by Motorola/Lenovo, Samsung, Sony, 3DRobotics, and others).
We'd love to learn about more NuttX use cases and enterprise deployments. Get in touch.

Apache Shardingsphere has attracted a huge 15,000+ stars and 5,000+ forks on GitHub.
A “Database Plus” it aims to build a standard layer and ecosystem above heterogeneous databases so users can “reuse” the storage capacity of existing fragmented databases in a distributed system.
As the project team puts it: “As the cornerstone of enterprises, relational database still takes a huge market share. Therefore, we prefer to focus on its increment instead of a total overturn. Apache ShardingSphere begin to focus on pluggable architecture from version 5.x, features can be embedded into project flexibility.
“Currently, the features such as data sharding, replica query, data encrypt, shadow database, and SQL dialects / database protocols such as MySQL, PostgreSQL, SQLServer, Oracle supported are all weaved by plugins. Developers can customize their own ShardingSphere just like building lego blocks. There are lots of SPI extensions for Apache ShardingSphere now and increase continuously.”
*Useful
**A wart on the insipid face of late capitalism.