
Data science is still, in most quarters, the remit of data scientists. But AI and Machine Learning are bringing advanced algorithmic logic founded in the principles, pillars and procedures of data science into the waking consciousness of non-technical professionals at all levels.
The so-called democratisation of advanced technology functions through what are typically cloud-based layers of abstraction and virtualisation has left a lot of waffling about LLMs and RAGs and DNNs in its wake in recent months. But deep-rooted technology advancements are indeed happening in our enterprise applications – including the ability to make use of real-time data and data streaming to power future AI applications.
Confluent, Inc a company founded to develop data streaming platform services based upon Apache Kafka (an open source project devoted to distributed event streaming services that are today used companies for high-performance data pipelines, streaming analytics, data integration and mission-critical applications), used the Current 2023 conference in San Jose this week to announce Data Streaming for AI, an initiative designed to accelerate organisations’ development of real-time AI applications.
(It's dubbed "Current" the "next generation of Kafka" summit, but hot new thing Flink was also a major talking point... More below.)
AI & vector database players
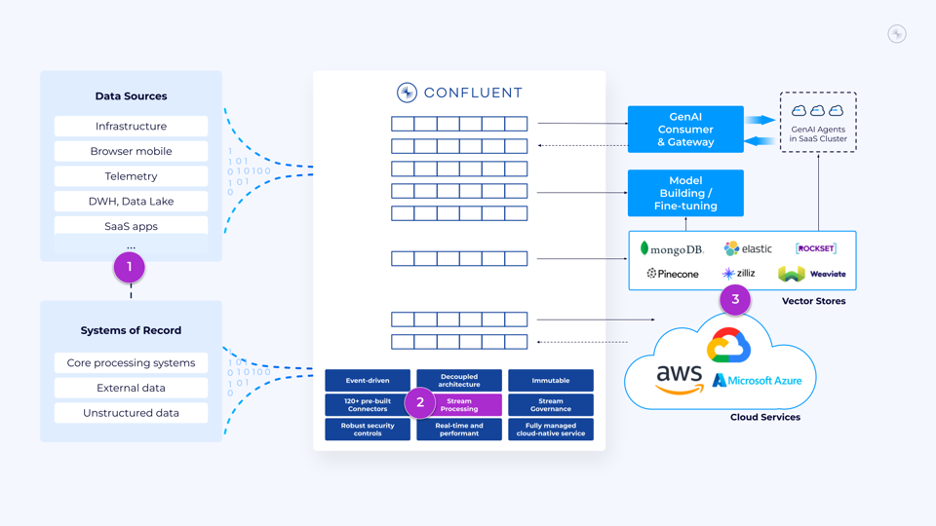
Confluent made much hay of the important industry union that needs to happen between the vector databases underpinning AI applications and the data streaming pipelines that could feed them and Confluent says it has addressed the gap between itself, as a data streaming specialist, and a key group of organisations that it classifies as significant players (yes the marketing people said "leading") in the vector database space.
Because Confluent wants to help customers bring what it defines as "fresh contextual data" into the mix here, the company is expanding partnerships with firms including MongoDB, Pinecone, Rockset, Weaviate and Zilliz to connect its governed and fully managed data streams with their vector search databases in a bid to be the one-stop streaming shop for AI application developers.
AI here, like there, was flavour of the month. So, what else?
Confluent also said it is delivering a new generative AI-powered assistant that helps customers generate code and answer questions about the data streaming environment with natural language.
To help IT teams get contextual answers they need to speed up engineering on Confluent, the Confluent AI Assistant turns natural language inputs like “What was my most expensive [data processing] environment last month?” or “Give me an API request to produce messages to my orders topic” into suggestions and what the company promises is ‘accurate code’ that’s specific to their deployment. This is made possible by combining publicly available information, such as Confluent documentation, with contextual customer information to provide specific, timely responses.
“Data streaming is a foundational technology for the future of AI,” said Jay Kreps, CEO and co-founder, of Confluent this week. “Continuously enriched, trustworthy data streams are key to building next-gen AI applications that are accurate and have the rich, real-time context modern use cases demand.
"We want to make it easier for every company to build powerful AI applications and are leveraging our expansive ecosystem of partners and data streaming expertise to help achieve that.”
Traditional ‘old fashioned’ AI
For the past decade, AI heavily relied on historical data, integrated with slow, batch-based point-to-point pipelines that rendered data stale and inconsistent by the time it arrived. CEO Kreps and team used their keynotes and breakout sessions in San Jose to explain why that's no longer adequate for the real-time AI use cases today's businesses are trying to launch, like predictive fraud detection, generative AI travel assistants, or personalized recommendations.
Compounding the problem are issues with poor data governance and scalability. As a result, the pace of AI advancements is stifled as developers are constantly tackling issues with out-of-date results.
"Although there’s significant growth in the number of companies experimenting with generative AI, many face roadblocks from a fractured data infrastructure that lacks real-time data availability and trust,” said Stewart Bond, vice president, data intelligence and integration software, IDC.
“Data management is the most important area of investment as organisations build an intelligence architecture that delivers insights at scale, supports collective learning and fosters a data culture. Those that get it right have seen a 4x improvement in business outcomes by removing real-time data availability and trust roadblocks through data streaming, governance, security and integration – so it’s worth the journey.”
Flink SQL
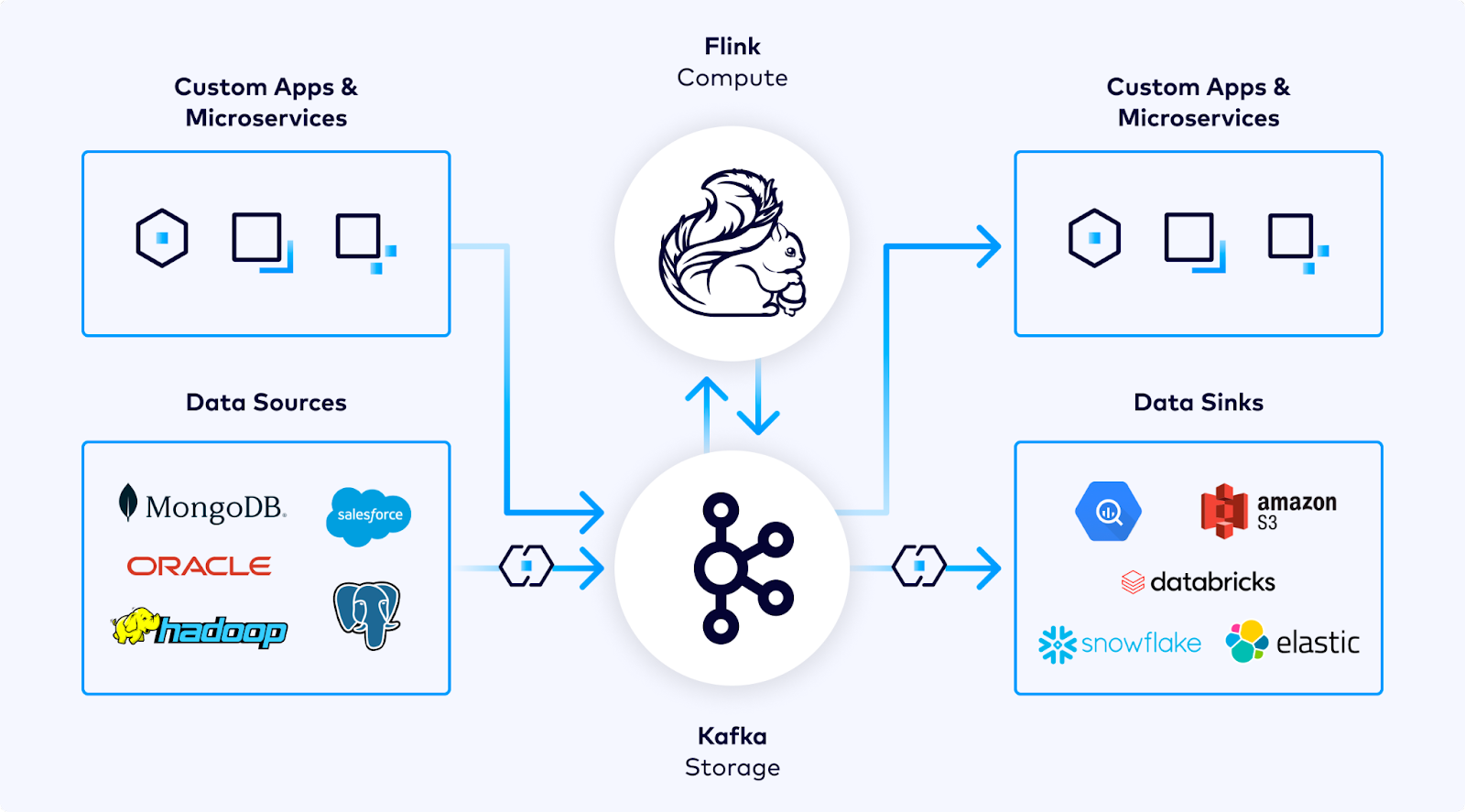
Looking ahead, over the next several months, Confluent says it will announce a series of updates to its newly announced Flink service for Confluent Cloud that bring AI capabilities into Flink SQL. (Flink on Confluent Cloud is a fully managed Flink service currently in preview across select regions on AWS; the company is offering it as a streaming compute layer for Kafka...)
But what is Flink?
As The Stack has previously put it, Apache Flink is an "open-source stream processing framework [that] supports batch processing and data streaming. Briefly, it can reliably process a tonne of data in real time, at pace; something that has become ever more important as enterprises look to react to data feeds as fast as possible (whether that’s Internet of Things data, user journey data/click streams for complex retail applications, or any other use case…)
"Use cases are diverse and range from event-driven microservices, to data pipelines for ETL: a fork of Flink is used by Alibaba to optimise search rankings in real time and by Capital one for real-time activity monitoring; Ericsson meanwhile used Flink to build a real-time anomaly detector for large infrastructures. Flink can perform stateful or stateless computations over data and has a lively community. It can handle up to 1.7 billion messages per second, according to users at Alibaba, which has a good use case example here."
Confluent said: "Flink serves as the streaming compute layer to your Kafka storage layer. It empowers developers to query and inspect data streaming into Kafka, along with functionality to enrich, curate, and transform those streams for improved usability, portability, and compliance. One of the great benefits of Flink is its ANSI standard implementation of Flink SQL—if you know SQL, then you know Flink SQL.
"Our Flink service takes Flink’s SQL API further by integrating the operational catalog with the rest of the Kafka ecosystem on Confluent Cloud. Customers with Kafka topics and schemas in Schema Registry will already have tables to browse and query in Flink SQL without having to wrangle with tedious CREATE TABLE statements or data type mappings that so often trip people up
On the main stage of Current in San Jose, Confluent demonstrated how Flink can make OpenAI API calls directly within Flink SQL. This, it said, unlocks new use cases for customers, such as rating the sentiment of product reviews or summarising vendors’ item descriptions in near real-time. The company says it will help alleviate the complexities of stream processing.
Around 2,500 data streaming enthusiasts attended this event this week and they’re nice people – apart from the fact that they walk around wearing T-shirts that say things like ‘Batch Is Dead’ -- and it’s good to see that Confluent doesn’t even put its name on the event and just calls the conference Current. AI is certainly that and on everyone's lips. Can Confluent democratise "cloud-native, serverless Flink services" as well? Time will tell. Promising "elastic autoscaling with scale-to-zero; evergreen runtime and APIs; usage-based billing" to the t-shirt wearers held promise. This was really was the "next-generation Kafka summit".








{kind=link}