
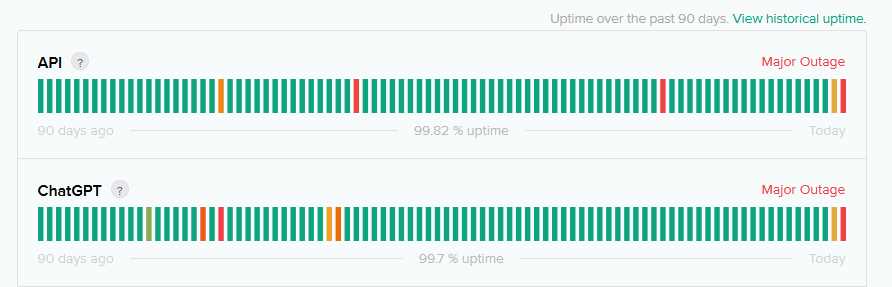
ChatGPT says that major outages across its web interface and API appear to be the result of a malicious attack – amid a resurgence in DDoS incidents.
The ChatGPT DDoS attacks, which affected the service for both free and paying customers, started November 7, as OpenAI unveiled a host of new offerings. They then escalated more severely on November 8.
OpenAI initially said on November 8 that it had “identified an issue resulting in high error rates across the API and ChatGPT, and we are working on remediation" and suggested that these had been fixed.
(The company's engineers have earlier said that on ChatGPT's launch it was so successful that they thought legitimate traffic was a DDoS attack, and CEO Sam Altman this week suggested that the outages were the result of interest in its new services “far outpacing our expectations.”)
But in its latest status update the company now says that "we are dealing with periodic outages due to an abnormal traffic pattern reflective of a DDoS attack. We are continuing work to mitigate this..."
The attacks have been claimed by Russian threat group "anonymous Sudan" which said in its Telegram channel that the attacks were due to OpenAI's support of Israel.
The incident comes less than a month after AWS, Cloudflare, and Google were hit with record-breaking DDoS attacks that exploit a zero day (allocated CVE-2023-44487) in the HTTP/2 protocol that is used by every modern web server – with the DDoS type dubbed "Rapid Reset."
See also: Most of the internet exposed to HTTP/2 zero day, as hyperscalers report record DDoS attacks
Cloudflare noted at the time that the record DDoS attacks, which reached 398 million requests per second, had been generated with a botnet of just 20,000 machines, worrying, it added, given that there are botnets today that are made up of hundreds of thousands or millions of machine.
"Given that the entire web typically sees only between 1–3 billion requests per second, it's not inconceivable that using this method could focus an entire web’s worth of requests on a small number of targets.”
It also comes a day after CISA confirmed that another vulnerability was being used in the wild to generate DDoS attacks, pointing to CVE-2023-29552, a bug in the Service Location Protocol (SLP, RFC 2608) that allows an unauthenticated, remote attacker to register arbitrary services; allowing attackers to use spoofed UDP traffic to conduct DDoS attacks "with a significant amplification factor."
The outages will re-emphasise the concerns of enterprise customers relying on the API to power their own customer-facing LLM-powered offerings that OpenAI needs to work on its resilience – and given that OpenAI runs on Microsoft infrastructure which has been resilient to/shielded against very large scale DD0S attacks, suggest that either they have been particularly severe or taken a unique approach to flooding OpenAI's infrastructure, perhaps with automated requests that clog up GPU and GPU RAM capacity.
The incident also points anew to a broader resurgence of DDoS attacks, which for some years had started to seem like a manageable script kiddie nuisance but as per the examples above, appear a renewed threat in recent months
ChatGPT DDoS attacks:
Stepping back from the near-term apparent ChatGPT DDoS incident, scaling up as fast as the AI company has has put unprecedented pressure on OpenAI's infrastructure, even with the backing of deep-pocketed Microsoft.
As one OpenAI engineer recently told developers at a conference: "We've discovered that bottlenecks can arise from everywhere: memory bandwidth, network bandwidth between GPUs, between nodes, and other areas. Furthermore, the location of those bottlenecks will change dramatically based on the model size, architecture, and usage patterns."
In particular, caching (KV cache) the “math” ChatGPT has done – to turn users request into tokens, then a vector of numbers, multiply that through “hundreds of billions of model weights” and then generate “your conference speech” – places big demands on memory in its data centres.
OpenAI’s Evan Morikowa earlier said: “You have to store this cache in GPU in this very special HBM3 memory; because pushing data across a PCIe bus is actually two orders of magnitude slower than the 3TB a second I get from this memory… it's [HBM3] so fast because it is physically bonded to the GPUs and stacked in layers with thousands of pins for massively paralleled data throughput…” (It is used to store model weights).
"So like any cache, we expire once this fills up, oldest first. If we have a cache miss, we need to recompute your whole Chat GPT conversation again. Since we share GPU RAM across all the different users, it's possible your conversation can get evicted if it goes idle for too long. This has a couple of implications. One is that GPU RAM is actually one of our most valuable commodities. It's frequently the bottleneck, not necessarily compute. And two, cache misses have this weird massive nonlinear effect into how much work the GPUs are doing because we suddenly need to start recomputing all this stuff. This means when scaling Chat GPT, there wasn't some simple CPU utilization metric to look at. We had to look at this KV cache utilization and maximize all the GPU RAM that we had.”
Both OpenAI and other large language model companies are "discovering how easily we can get memory-bound" he added, noting that this limits the value of new GPUs: "Nvidia kind of had no way of knowing this themselves since the H100 designs got locked in years ago and future ML architectures and sizes have been very difficult for us and anybody to predict. In solving all these GPU challenges, we've learned several key lessons [including] how important it is to treat this as a systems engineering challenge."
To be updated with more details as we have them.








{kind=link}