Microsoft President Brad Smith has fired an apparent warning shot at NVIDIA – which underpins the vast majority of its and OpenAI’s AI training and inference workloads – claiming in a blog that a new generation of AI firms is “moving now from… GPUs to AI Accelerators with Tensors.”
He made the comments as analysts at consultancy Omdia estimated that Microsoft had bought 485,000 of Nvidia’s “Hopper” chips; far ahead of Meta, which bought 224,000 Hopper chips, or hyperscaler rivals.
Smith, who said that Redmond is on track this year to invest $80 billion building out “AI-enabled datacenters to train AI models”, made the comments in a January 3 post titled the “Golden Opportunity for American AI”. He wrote 14 months after Microsoft unveiled two homegrown semiconductors, including its “Maia AI Accelerator”, and an Arm-based CPU dubbed Cobalt for general purpose compute workloads.
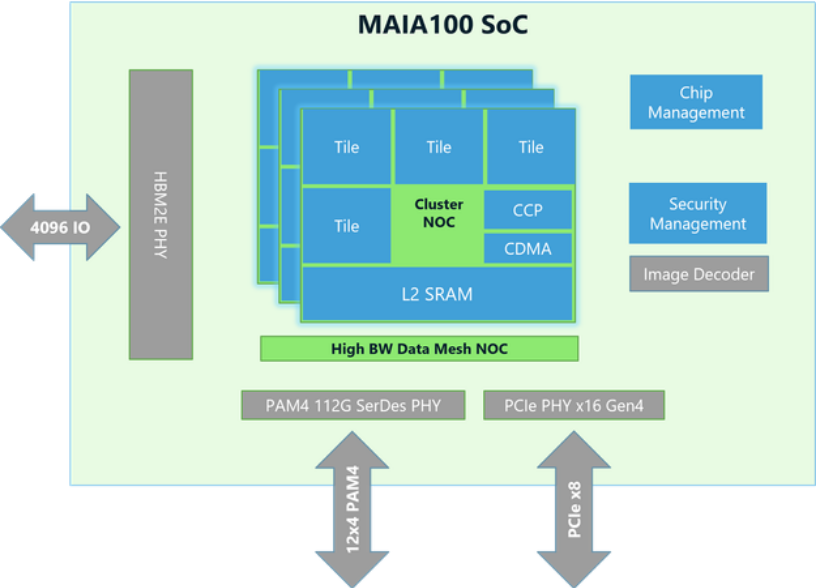
Five months ago Microsoft shared more details on its Maia AI Accelerator: The chip measures ~820mm2. It is fabbed on TSMC’s N5 process using the Taiwanese firm’s COWOS-S interposer technology.
Microsoft said that it provides 1.8 terabytes per second of bandwidth and 64 gigabytes of capacity for AI-scale data handling; an SDK enables “quick deployment of models to Azure OpenAI Services” it claims. (The FT says that Microsoft installed 200,000 Maia chips in its data centres in 2024 and there can be little doubt that Smith was talking up Redmond’s own chips.)
(In December 2024, however, Microsoft lost one of Maia’s key architects, Intel veteran Rehan Sheikh, who has left Redmond to take on a role as VP of global silicon chip technology and manufacturing at Google Cloud.)
Microsoft President Brad Smith’s blog also talked up the need for a “broad and competitive technology ecosystem, much of which is based on open-source development” and flagged the risk of China “exporting” AI models that become an industry standard globally at a lower cost.
He wrote: “The Chinese wisely recognize that if a country standardizes on China’s AI platform, it likely will continue to rely on that platform in the future. The best response for the United States is not to complain about the competition but to ensure we win the race ahead…[and] move quickly and effectively to promote American AI as a superior alternative.”
Enter DeepSeek?
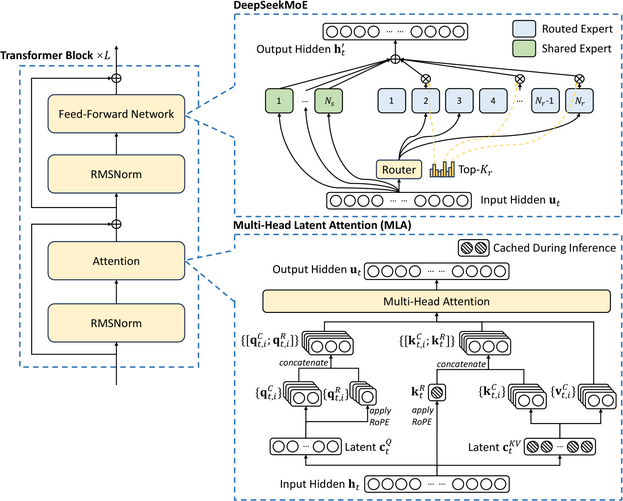
Smith’s post came as Chinese AI lab DeepSeek said that it had trained and shipped a powerful Large Language Model for a mere $6 million on 2048 low-power, export control-friendly NVIDIA H800 chipsets. DeepSeek’s Mixture-of-Experts design uses 671 billion total parameters but activates only 37 billion for each task, sharply reducing compute needs. As investor Edward F Boyle puts it: “They pioneered new load-balancing strategies and an FP8 mixed precision framework that eliminated the usual instabilities in large model training.” DeepSeek detailed its approach here.
An illustration of the basic architecture of DeepSeek-V3A vA v
Major disruption looks set to happen in the generative AI space in 2025. Microsoft’s investment of $80 billion this year may involve a lot of capital being reallocated to its own custom hardware after a colossal shopping spree on NVIDIA in 2024, but with Chinese propositions emerging thick and fast at far lower cost, Smith’s emphasis that “American companies currently have better technology, from chips to AI models to software applications” and that “many U.S. companies, including Microsoft, have invested heavily in building AI that is more trustworthy than most products from China” may not resonate in all quarters of the globe. Competition – to NVIDIA and to American LLMs – is certainly heating up.
Sign up for The Stack
Interviews, Insight, Intelligence for Digital Leaders
No spam. Unsubscribe anytime.
The link has been copied!
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.