Microsoft has released a new agentic synthetic data generator that appears to disprove fears that training models on artificially-created data causes them to "collapse".
Academics previously warned that feeding large language models (LLMs) information that has been made up by other AIs makes them "misperceive reality" and start to spew out nonsense - with the problem snowballing as successive generations of models are trained on the "polluted" gibberish produced by their forebears.
But Microsoft's new Orca-AgentInstruct has been shown to dramatically improve the pre-training of models, suggesting that synthetic data does not necessarily cause models to buckle under the weight of made-up information.
In a blog post, Arindam Mitra, Senior Researcher Ahmed Awadallah, Partner Research Manager and Yash Lara, Senior PM, wrote: "Research indicates that pre-training models on synthetic data produced by other models can result in model collapse, causing models to progressively degrade.
"Similar concerns have been raised regarding the use of synthetic data for post-training, suggesting that it might lead to an imitation process where the trained model learns only stylistic features rather than actual capabilities.
"This discrepancy may be attributed to the challenge of generating high-quality and diverse synthetic data. Successful use of synthetic data involves significant human effort in curating and filtering the data to ensure high quality."
Graphics showing the performance boost unlocked by AgentInstruct (Image: Microsoft)
How does Orca-AgentInstruct work?
Microsoft's work on synthetic data started with two previous models, Orca and Orca 2, which "demonstrated the power of using synthetic data for the post-training of small language models and getting them to levels of performance previously found only in much larger language models."
Microsoft's synthetic data factory is capable of generating "diverse and high-quality data at scale", using an agentic framework to generate datasets consisting of both prompts and responses from raw data sources and "paving the way to building a synthetic data factory for model fine-tuning."
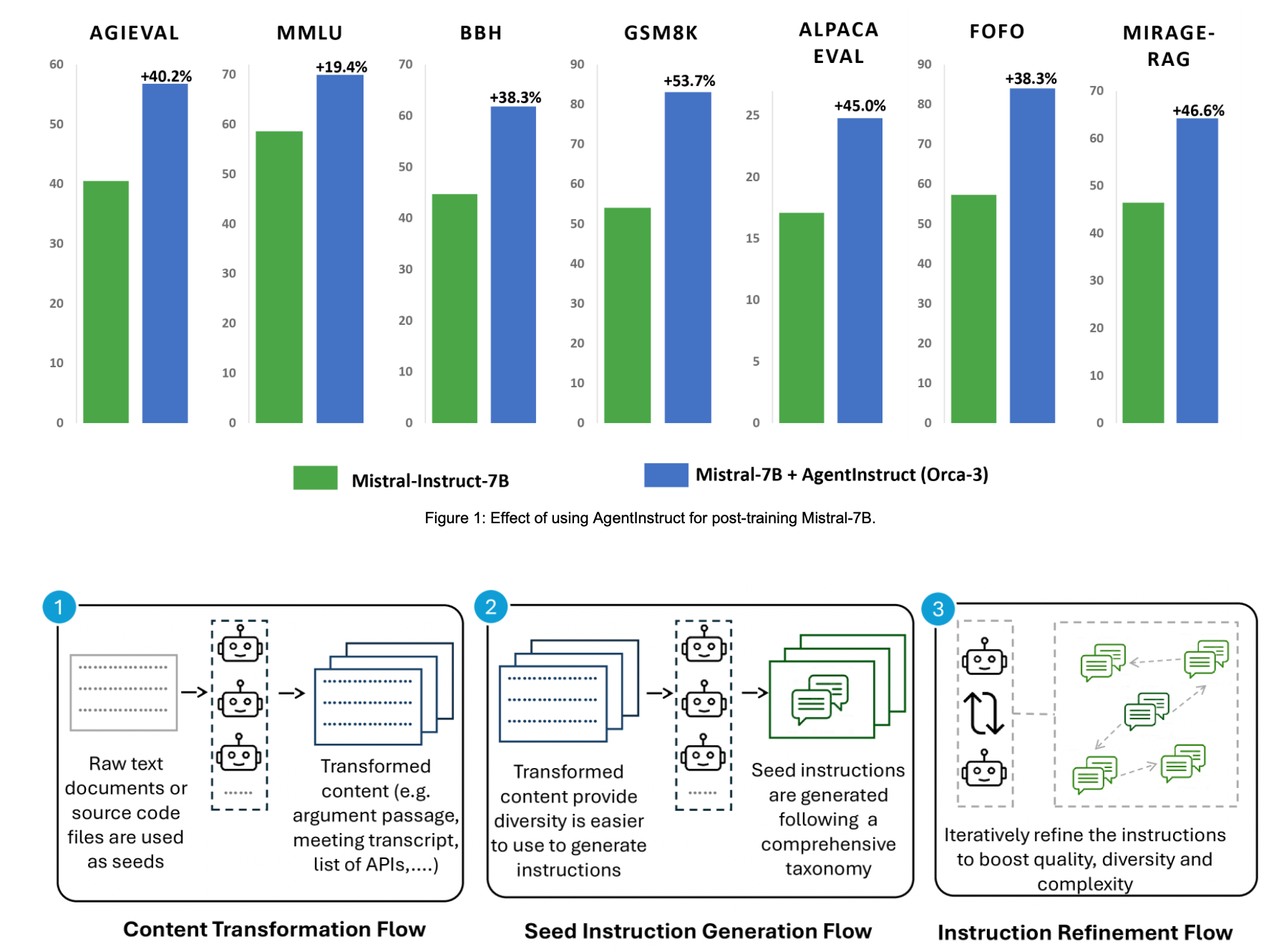
Microsoft said the "efficacy" of this approach is demonstrated by the "substantial" improvement it observed when fine-tuning a Mistral 7-billion-parameter model using a dataset of 25 million pairs generated by AgentInstruct.
The fine-tuned model, which was named Orca-3-Mistral, achieved a big performance hike on several benchmarks, including 40% on AGIEval, 19% on MMLU, 54% on GSM8K, 38% on BBH, 45% on AlpacaEval, and a 31.34% reduction of "inaccurate or unreliable results across multiple summarization benchmarks."
Typically, generating synthetic data for post-training or finetuning relies on an existing prompt set that is fed into models or used to generate more instructions. Microsoft's new approach relies on a technique called "generative teaching" which focuses on "generating an abundant amount of diverse, challenging, and high-quality data to teach a particular skill to an AI model".
AgentInstruct uses raw documents as its input and spits out demonstration and feedback data. When it uses generic data as seeds, it can be used to teach an LLM a "general capability" such as writing, reasoning, or retrieval-augmented generation (RAG). Domain-specific data from sectors such as retail or finance can also be used as seeds to "improve the model in a certain specialization".
It uses GPT-4 as well as search and code interpreters to create high-quality data, before creating prompts and responses using a set of specialised agents drawing on LLMs and a large taxonomy of more than 100 subcategories to "ensure diversity and quality."
"Using raw data as seeds offers two advantages," Microsoft wrote. "It is plentiful, allowing AgentInstruct to generate large-scale and diverse datasets, and it encourages learning general skills instead of benchmark-specific ones by avoiding using existing prompts."