mícrosoft

Microsoft has unveiled a "radically different approach" to graph-enabled RAG called LazyGraphRag which is certainly no slouch, layabout or spendthrift.
Redmond researchers claimed its new RAG offers "inherent scalability in terms of both cost and quality", exhibiting "strong performance across the cost-quality spectrum". It also drives down the cost of global searches of entire datasets, whilst making local searches more effective.
In other words: it's not lazy.
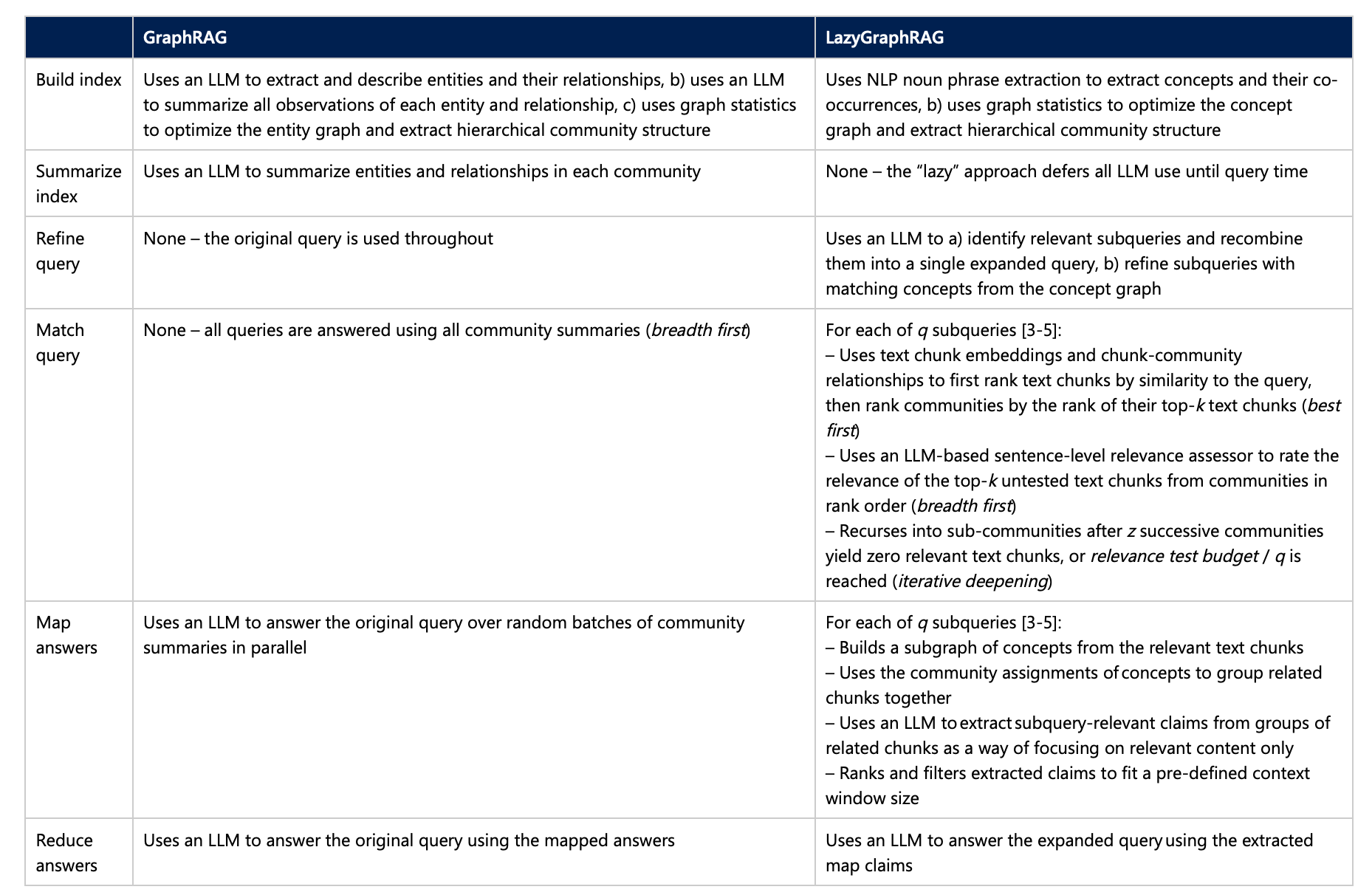
Lest ye forget, GraphRAG is a portmanteau of the words "Graphs" and RAG (Retrieval Augmented Generation). It is a technique for gaining a deeper understanding of word-based datasets using text extraction, network analysis, and LLM prompting and summarization through a single end-to-end system. Find out more on Microsoft's website.
LazyGraphRag incorporate both VectorRAG and GraphRAG "while overcoming their respective limitations".
"LazyGraphRAG shows that it is possible for a single, flexible query mechanism to substantially outperform a diverse range of specialized query mechanisms across the local-global query spectrum, and to do so without the up-front costs of LLM data summarization," Microsoft wrote.
"Its very fast and almost-free indexing make LazyGraphRAG ideal for one-off queries, exploratory analysis, and streaming data use cases, while its ability to smoothly increase answer quality with increasing relevance test budget makes it a valuable tool for benchmarking RAG approaches in general."
VectorRAG vs GraphRAG
Vector RAG is also known as semantic search and is a "form of best-first search that uses the similarity with the query to select the best-matching source text chunks", Microsoft explained.
"However, it has no sense of the breadth of the dataset to consider for global queries," it continued.
"GraphRAG global search is a form of breadth-first search that uses the community structure of source text entities to ensure that queries are answered considering the full breadth of the dataset," the researchers wrote. "However, it has no sense of the best communities to consider for local queries."
This second technique is considered more effective than conventional vector RAG when answering global queries about an entire dataset, such as “what are the main themes?" or "what does this information show about X?". It excels in delivering answers involving breadth.
Vector RAG, on the other hand, is best at local queries where the answer looks a lot like the question, which Microsoft said is "typically the case" for questions involving "who, what, when, where" questions. Which is where the phrase best-first comes from.
What is LazyGraphRAG?
LazyGraphRAG combines best-first and breadth-first search dynamics in an iterative deepening manner - in which a search is first carried out at limited depth before iteratively diving deeper and deeper into a dataset.
Microsoft said LazyGraphRAG's data indexing costs are identical to vector RAG and just 0.1% of the costs of full GraphRAG.
"The same LazyGraphRAG configuration also shows comparable answer quality to GraphRAG Global Search for global queries, but more than 700 times lower query cost, it added. "For 4% of the query cost of GraphRAG global search, LazyGraphRAG significantly outperforms all competing methods on both local and global."
Why is LazyGraphRAG described as lazy?
Microsoft answered this question as follows: "Compared to the global search mechanism of full GraphRAG, this approach is 'lazy' in ways that defer LLM use and dramatically increase the efficiency of answer generation. Overall performance can be scaled via a single main parameter – the relevance test budget – that controls the cost-quality trade-off in a consistent manner.
So the industrious RAG is “lazy” because it optimises the use of large language models (LLMs) by deferring their application until absolutely necessary. Instead of processing the entire dataset upfront, it carries out initial relevance testing, which analyses smaller data subsets to identify potentially pertinent information.
After these tests are complete, the system engages more resource-intensive LLMs for deeper analysis.
Which reminds us of a quote from Bill Gates when he worked at Microsoft, rather doing whatever it is he does now:
“I choose a lazy person to do a hard job. Because a lazy person will find an easy way to do it.”