
Large language models offer threat actors a range of innovative opportunities to target their victims.
We've previously heard that overloading LLMs with dodgy data can cause model collapse, as well as warnings that "data poisoning" lets the bad guys trick AI models into generating malicious responses.
Now, researchers have designed a new type of "fast and transferable" adversarial attack that "delivers significant speed improvements" over pre-existing strategies, enabling "victim models" to be attacked up to twenty times faster than previously possible.
An adversarial attack attempts to deceive or manipulate a machine learning model or system by providing it with carefully crafted inputs designed to cause the model to make mistakes or produce incorrect outputs. These attacks are often very subtle and can be difficult to detect.
"Recently, large language models (LLMs) such as ChatGPT and LLaMA have demonstrated considerable promise across a range of downstream tasks," academics from China's Harbin Institute of Technology wrote in a pre-print paper.
"Subsequently, there has been increasing attention on the task of adversarial attack which aims to generate adversarial examples that confuse or mislead LLMs."
They added: "The task of adversarial attack aims at generating perturbations on inputs that can mislead the output of models. These perturbations can be very small, and imperceptible to human senses."
READ MORE: Gandalf exposes the major GenAI security threats facing enterprises
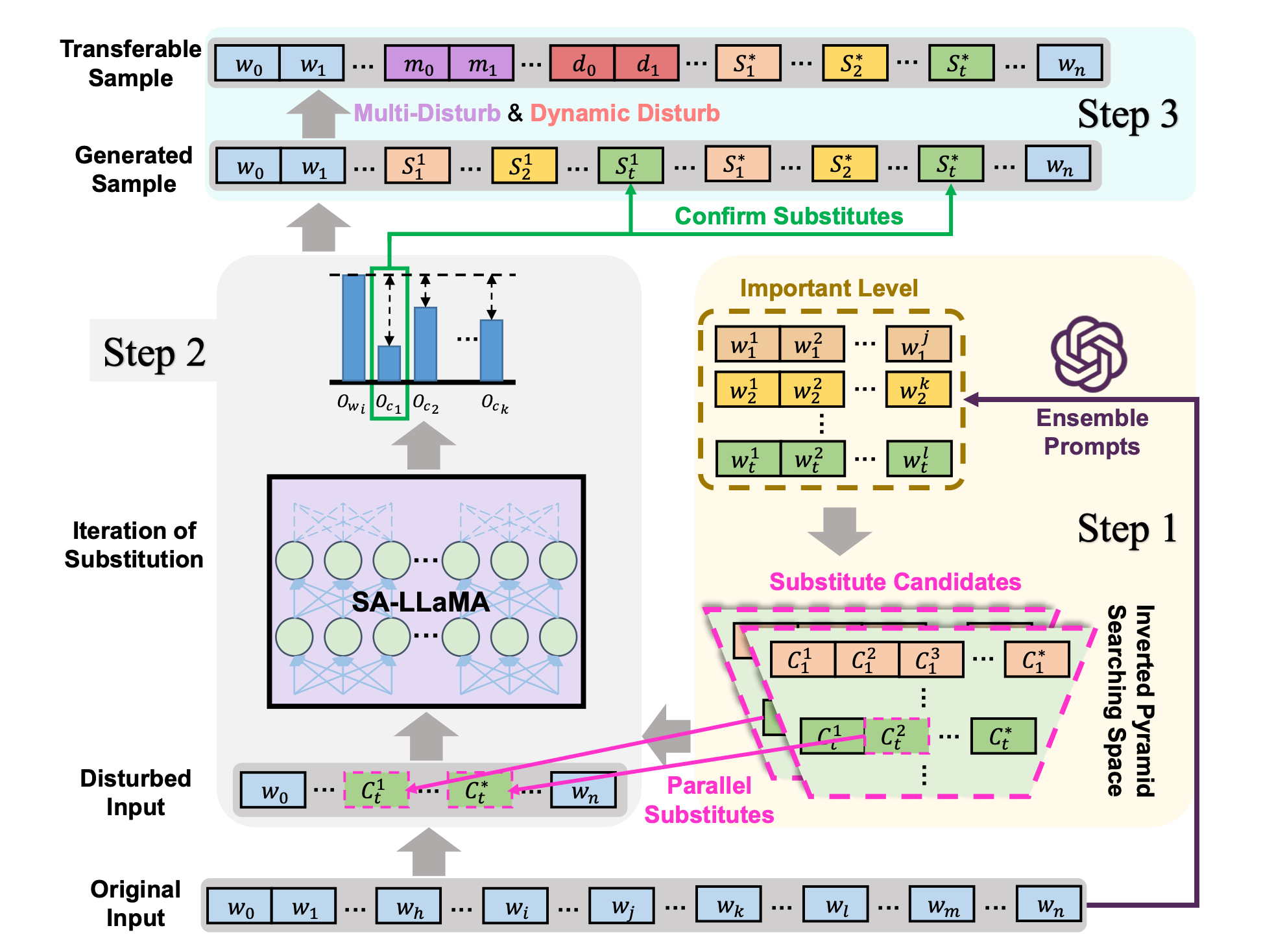
The academics explained that adversarial attacks typically follow a two-step process, ranking the importance of a token (a unit of data such as text or images processed by GenAI models) and then replacing it to manipulate outputs.
This attack method is slow and hard to scale, because an adversarial attack that works on one model may not work effectively on another.
"The portability of adversarial samples generated by existing methods is poor, since perturbations generated according to a specific pattern of one model do not generalise well to other models," the researchers wrote.
WTF is TF-Attack?
TF-Attack can generate adversarial samples by "synonym replacement", which means inserting the wrong words into datasets to "precipitate a notable decline in the performance of victim models".
It employs ChatGPT or another model as an "external third-party overseer" to "identify important units with the input sentence, thus eliminating the dependency on the victim model." In other words, it uses an external model as an attack dog, reducing reliance on the victim model and giving the adversarial AI the ability to target a wider range of victims.
Additionally, TF-Attack can replace several words within the priority queue simultaneously rather than one at a time.
"This approach markedly reduces the time of the attacking process, thereby resulting in a significant speed improvement," the researchers continued.
TF-Attack also employs "two tricks" called Multi-Disturb and Dynamic-Disturb to "enhance the attack effectiveness and transferability of generated adversarial samples".
Adversarial attacks can involve inserting malicious characters, words or sentences within inputs to radically alter outputs. The Chinese academics went one step further to "introduce random disturbances", which have the effect of "reducing model confidence".
READ MORE: Microsoft's RAG Copilot can be tricked into leaking enterprise secrets, researchers claim

Multi-Disturb introduces a variety of disturbances within the same sentence, whereas Dynamic-Disturb analyses the length and structural distribution of input sentences to change the output.
"Our experiments confirm that these two tricks can be adapted to almost all text adversarial attack methods, significantly enhancing transferability and increasing the ability of adversarial samples to confuse models through adaptive post-processing," the team wrote.
"We believe that TF-ATTACK is a significant improvement in creating strong defenses against adversarial attacks on LLMs, with potential benefits for future research in this field," they concluded.







{kind=link}