LLMs

The old cliche of "rubbish in, rubbish out" has never been truer.
Most of the big large language models (LLMs) have sifted more sewage than a Thames oyster, with models like GPT-4 trained on the never-ending stream of bilge and bloviation that characterises much of the internet.
Synthetic data generated by AI offers a new way of training models without exposing them to the messy, heavily biased and often totally false information that's lurking out there online.
But there could be a problem. Researchers from a group of top universities in the UK have warned that AI suffers from "model collapse" when trained on data generated by other models.
This is likely to become a growing issue when the internet becomes filled with the garbage generated by ChatGPT and whatever other LLMs rise up to take its place.
READ MORE: Microsoft unveils a large language model that excels at encoding spreadsheets
"Generative artificial intelligence (AI) such as large language models (LLMs) is here to stay and will substantially change the ecosystem of online text and images," they wrote in a study published in Nature exploring what might happen "once LLMs contribute much of the text found online."
"We find that indiscriminate use of model-generated content in training causes irreversible defects in the resulting models, in which tails of the original content distribution disappear. We refer to this effect as ‘model collapse’."
The researchers claimed their study not only highlights the problem but "portrays its ubiquity among all learned generative models."
"We demonstrate that it must be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web," they continued. "Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of LLM-generated content in data crawled from the internet."
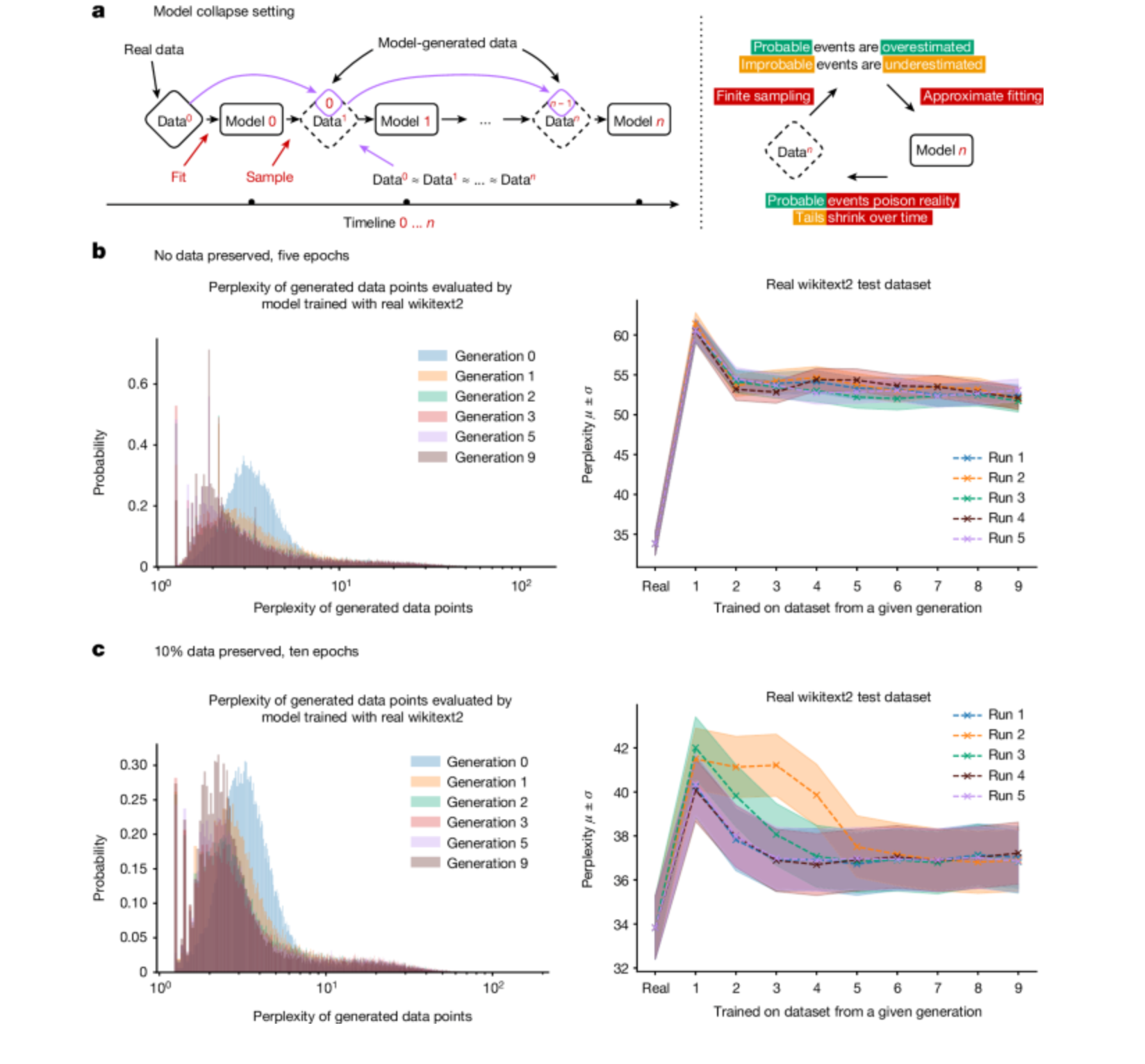
The team defined model collapse as "a degenerative process affecting generations of learned generative models, in which the data they generate end up polluting the training set of the next generation." Once an LLM is "trained on polluted data," they "misperceive reality."
Researchers set out three reasons for model collapse.
The primary issue is "statistical approximation error" which "arises owing to the number of samples being finite, and disappears as the number of samples tends to infinity."
"This occurs because of a non-zero probability that information can get lost at every step of resampling," the academics explained.
The second is "functional expressivity error."
"In particular, neural networks are only universal approximators as their size goes to infinity," the academics continued. "As a result, a neural network can introduce non-zero likelihood outside the support of the original distribution or zero likelihood inside the support of the original distribution."
Finally comes "functional approximation error, which arises "primarily from the limitations of learning procedures" and "the limit of infinite data and perfect expressivity at each generation."
The academics made the following suggestion about how to combat the issue: " To sustain learning over a long period of time, we need to make sure that access to the original data source is preserved and that further data not generated by LLMs remain available over time.
"One option is community-wide coordination to ensure that different parties involved in LLM creation and deployment share the information needed to resolve questions of provenance. Otherwise, it may become increasingly difficult to train newer versions of LLMs without access to data that were crawled from the Internet before the mass adoption of the technology or direct access to data generated by humans at scale."