
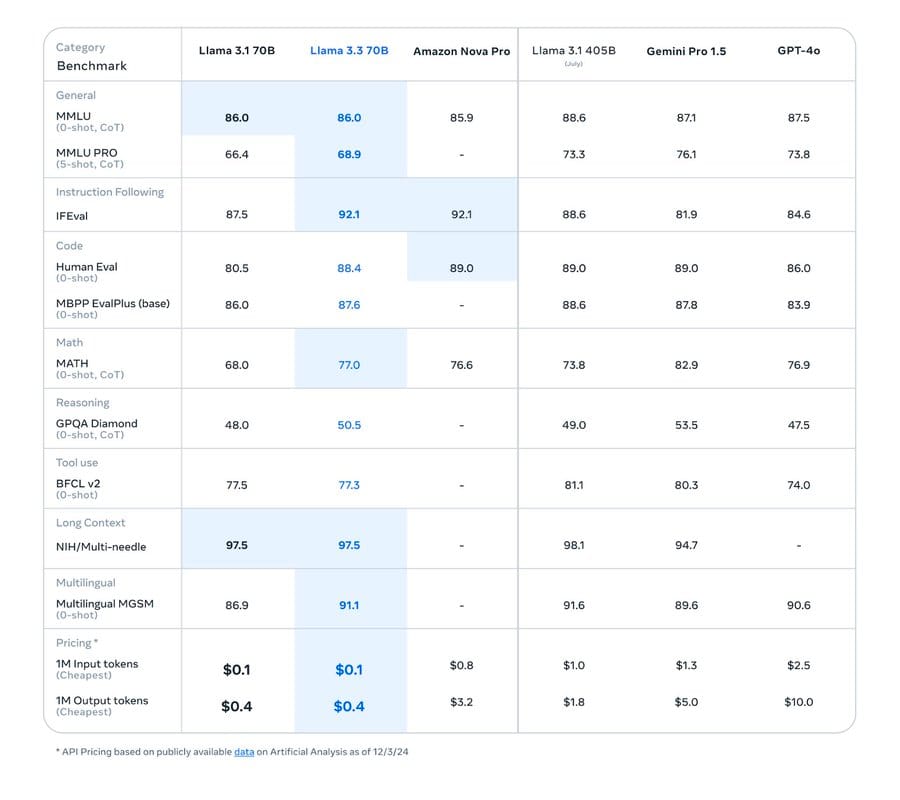
A new Large Language Model (LLM) from Meta, Llama 3.3 70 is as powerful as its 405 billion parameter predecessor but cheaper to run.
Meta’s new Llama 3.3 LLM is also licensed to create synthetic data that can be used to train your own models. (Among its 15 trillion tokens of training data were 25 million synthetic ones, said Meta on a model card.)
“Llama 3.3 Community License allows for these use cases” it affirmed.
Synthetic data generated by LLMs can help "remove the need to manually collect, annotate and review large datasets and be used to fine-tune smaller language models for machine local inference", notes Cole Murray.
See also: Generating Synthetic Data With LLMs For Fine-tuning
Meta released the new model on December 6, with its generative AI chief Ahmad Al-Dahle posting on X that Llama 3.3 70 “delivers the performance of our 405B model but is easier and more cost-efficient to run…”
It was trained for 39.3 million GPU hours on NVIDIA H100s. It supports English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
Its release comes as a growing number of open source LLMs proliferates – including the likes of the Qwen models from Alibaba Cloud, which are performing highly on numerous LLM benchmarks. These are licensed under a mix of Apache 2.0 and proprietary "Qwen" licenses. (Fine-tuned versions of Qwen are dominating Hugging Face's Open LLM leaderboard.)
Llama 3.3: Greater accuracy, lower cost
Llama 3.3 represents a notable update to Meta’s burgeoning family of “open-source” large language models. It features the ability to generate JSON outputs for function calling, step-by-step reasoning and greater coverage and accuracy for a wide range of programming languages.
Its released capped a notable week in the generative AI space that also saw AWS launch its low-cost Nova models and OpenAI make the controversial move to charge $200/month for its new “ChatGPT Pro” – which it said adds more compute for users of its recently released OpenAI o1 LLM.
Meta’s Al-Dahle said Llama 3.3 features the “latest advancements in post-training techniques including online preference optimization, this model improves core performance at a significantly lower cost.”
See also: Bloomberg, Tetrate team up on open-source AI API Gateway
“Llama 3.3 an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety” Meta added.
LLama 3.3 is GA, including via Huggingface, where a repository contains two versions of Llama-3.3-70B-Instruct, for use with transformers and with the original llama codebase. It is also available on IBM’s Watsonx.ai.
Whilst many organisations are still experimenting with LLM use cases and (per recent enterprise conversations) a significant number are still working with a single commercial model via a trusted partner, a growing number are also taking a multi-model approach, under which they are looking to bring together multiple models and modalities in a "compound AI" system of cloud-based or locally run LLMs and SLMs.







{kind=link}