LLMs

The cost of generating responses from a large language model (LLM) is exhibiting a trend comparable to three of the tech industry's most famous "laws", the VC Andreessen Horowitz has claimed.
A process called LLM inference - generating a response - has been getting dramatically cheaper every year at a rate that dwarfs previous mega-trends such as Moore's Law, Edholm’s Law and Dennard scaling - although it's not clear whether this pattern will continue into the future.
But before we explain the argument, here's a quick recap on these three laws.
Moore's Law predicted that the number of transistors on a microchip doubles approximately every two years, meaning the cost of computing effectively halves (although Moore's Second Law states the cost of building a chip fab doubles every four years as complex processors become more difficult to design and build).
Edholm’s Law predicts that data transmission speeds and the bandwidth of telecommunications networks doubles approximately every 18 months - an observation that has held true since the 1970s.
Finally, Dennard scaling, also known as MOSFET scaling, states that as transistors become smaller, their power density remains constant, allowing for higher performance without increasing power consumption. Proposed in 1974, this principle began to break down in about 2006 as chips became smaller, current leakage worsened, heat generation surged and the risk of thermal runaway increased - driving up energy costs.
READ MORE: House of Lords homegrown "sovereign" British LLM plan slammed as "pointless"
Why has the cost of LLM inference decreased?
In a blog post, Guido Appenzeller, an investor at Andreessen Horowitz, said the price decline in LLMs is "even faster than that of compute cost during the PC revolution or bandwidth during the dotcom boom."
"For an LLM of equivalent performance, the cost is decreasing by 10x every year," he wrote. "Given the early stage of the industry, the time scale may still change. But the new use cases that open up from these lower price points indicate that the AI revolution will continue to yield major advances for quite a while."
Perhaps confusingly, the VC dubbed this trend "LLMflation", which would suggest the cost is going up. "We’re calling this trend LLMflation, for the rapid increase in tokens you can obtain at a constant price," Appenzeller explained.
"To a large extent, it is a rapid decline in cost of the underlying commodity that drives technology cycles," he added. "In analyzing historical price data since the public introduction of GPT-3, it appears that - at least so far - a similar law holds true for the cost of inference in large language models (LLMs)."
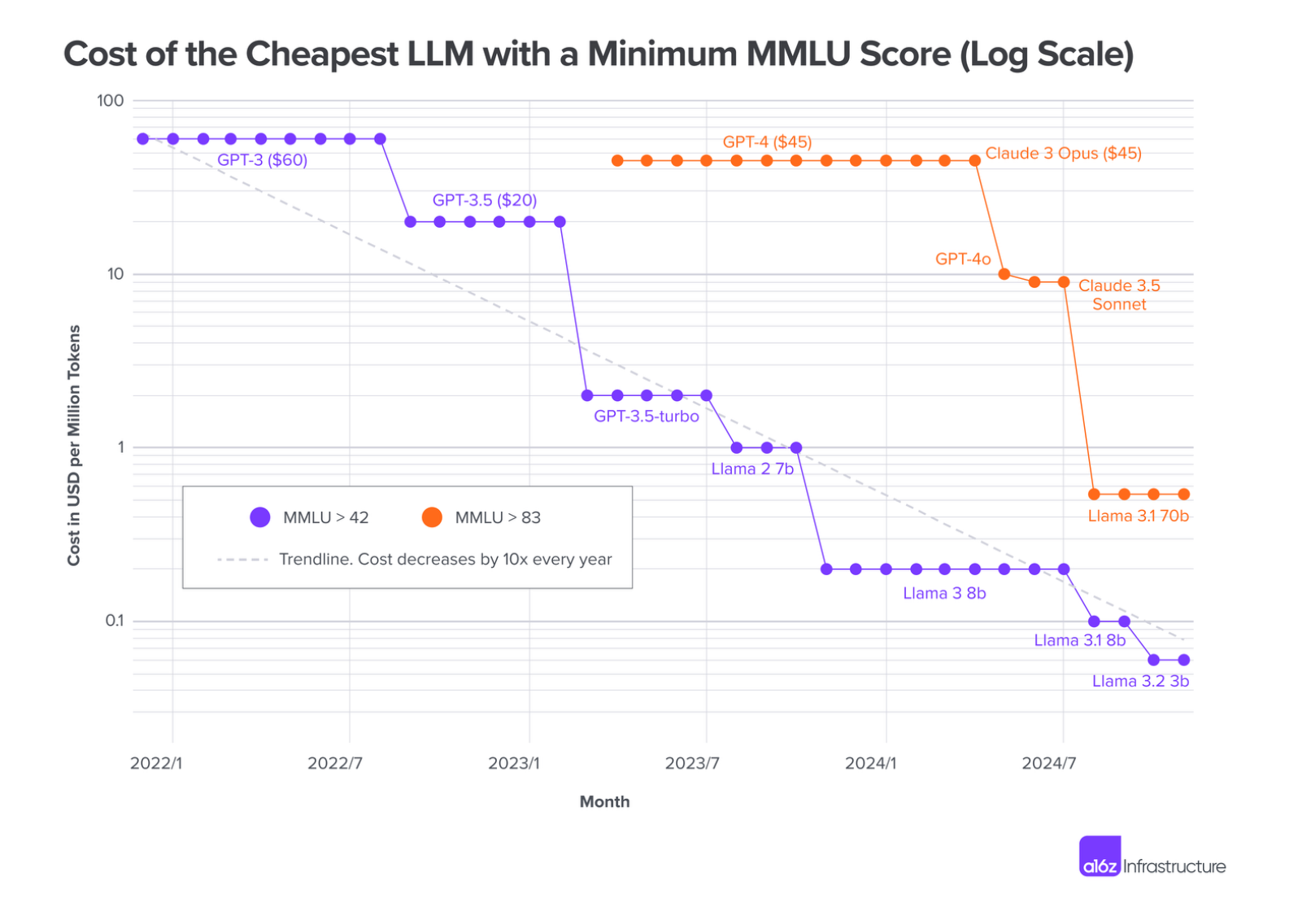
To determine the trend, the VC examined the performance of LLMs from OpenAI, Anthropic, and Meta using MMLU scores (Massive Multitask Language Understanding), a benchmark that evaluates the performance of models. This was then compared to historical pricing data.
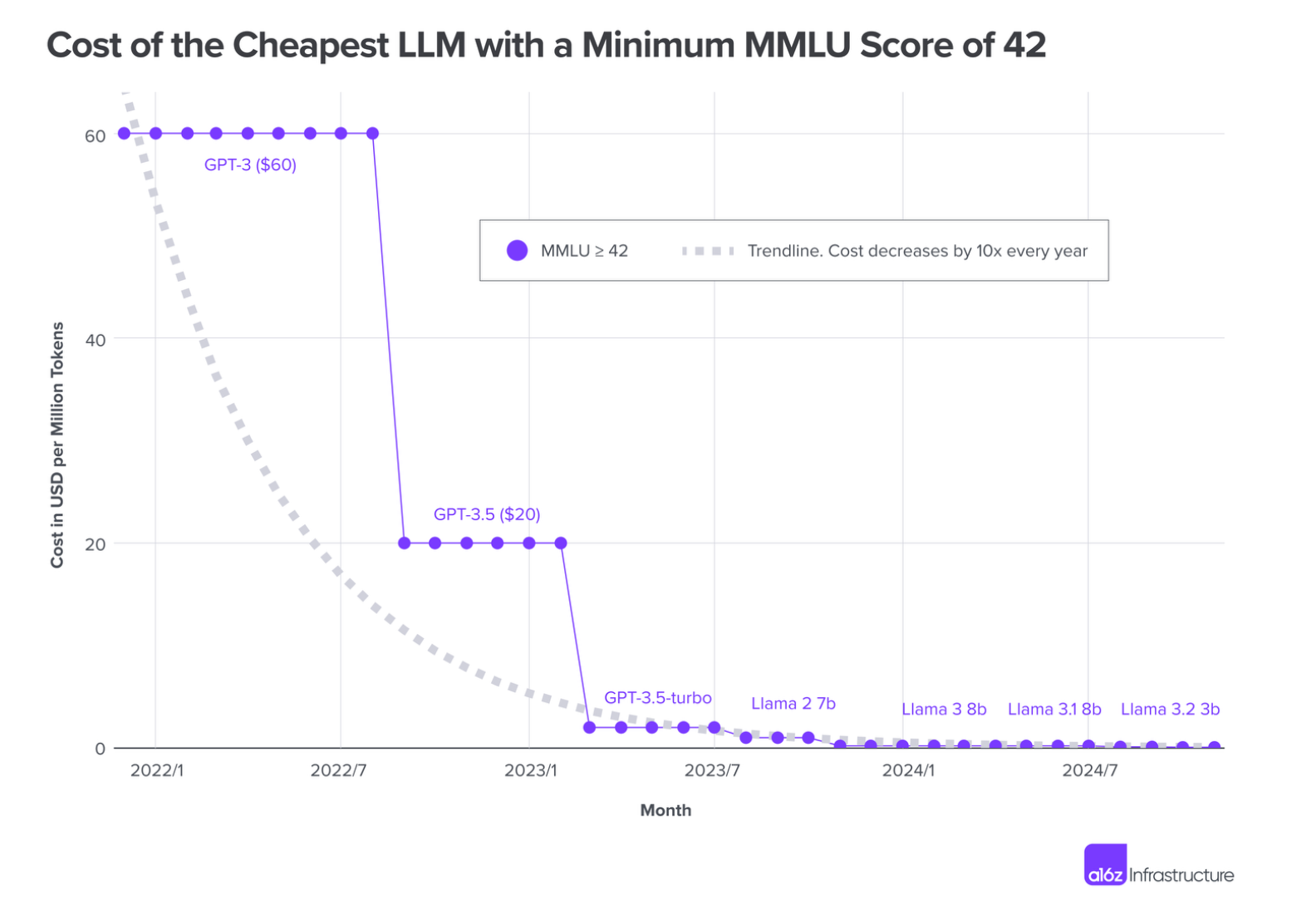
"When GPT-3 became publicly accessible in November 2021, it was the only model that was able to achieve an MMLU of 42 - at a cost of $60 per million tokens," the VC wrote. "As of the time of writing, the cheapest model to achieve the same score was Llama 3.2 3B, from model-as-a-service provider Together.ai, at $0.06 per million tokens. The cost of LLM inference has dropped by a factor of 1,000 in 3 years."
He added: "There is no question we are seeing an order of magnitude decline in cost every year."
Will LLM prices continue to plummet?
Appenzeller stopped short of coining his own eponymous law, admitting that the future is "hard to predict".
So far the cost reduction has been caused by the improved cost and performance of GPUs, as well as improved efficiency of model inference and software optimisation that reduced the amount of computer and memory bandwidth required to generate responses.
Smaller models are also proving that size doesn't matter in the LLM world, with a 1 billion parameter model now performing a 175 billion parameter model that was state of the art three years ago. Open-source models hosted by a range of competing providers also lowered prices, whilst advances in pre-training such as human feedback (RLHF) and direct preference optimization (DPO) have made the model more effective.
"While the cost of LLM inference will likely continue to decrease, its rate may slow down,' the VC continued. "The rapid decrease of LLM inference cost is still a massive boon for AI in general. Every time we decrease the cost of something by an order of magnitude, it opens up new use cases that previously were not commercially viable."