
New foundation models, new hardware, hundreds of new features… AWS’s re:Invent delivered its usual frenetic flurry of releases as CEO Matt Garman and guests like JPMorgan CIO Lori Beer took to the main stage on Tuesday.
Nova
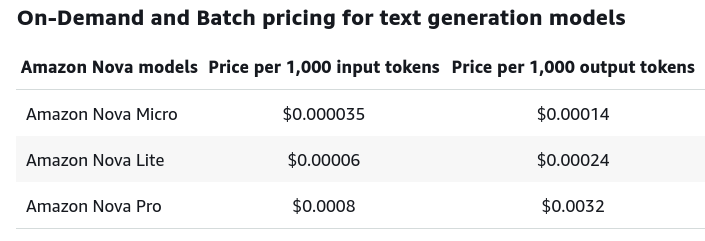
Among the highlights: Amazon Nova, a trio of new foundation models that AWS insisted was 75% cheaper than similar models on Bedrock – although they are currently only available in US East, with the option for cross-region inference workload bursting to US West for those so inclined.
(It can be hard to keep up as new LLMs spawn. One of The Stack’s highlights has been talking to startups like Fireworks.ai, founded by Meta veterans and working on “compound AI” that interweaves multiple open models for the best inference performance for a given use case.)
AWS also promised a new native “multimodal-to-multimodal” – or “any-to-any” modality model in the nascent Nova family in calendar 2025.
Trn2
Acronyms flew like crazy as did the “hardware porn” as AWS touted the likes of its new Amazon “Trn2” EC2 instances and “Trn2 “UltraServers” capable of scaling up to a massive 83.2 peak petaflops of compute and designed for training AI models with up to a trillion+ parameters.
“"Independent inference performance tests for Meta's Llama 405B showed that Amazon Bedrock, running on Trn2 instances, delivers more than 3x higher token-generation throughput compared to other available offerings by major cloud providers," said AWS, as it took the instances powered by its Trainium2 chips to general availability this week. Claude 3.5 Haiku now runs 60% faster on AWS Trainium 2 Anthropic added.
See also: A $300 million cloud bill triggered a rethink - and a shopping spree on modular hardware
Customers can "reserve up to 64 instances for up to six months, with reservations accepted up to eight weeks in advance" said AWS's Jeff Barr.
Amazon also teased its Trainium 3, Arm-powered chips. The first Trainium3-based instances are expected to be available in late 2025. These will be fabbed on a cutting edge 3nm node and power a new supercomputer “Project Rainier” – set to be one of the world’s largest AI compute clusters. Anthropic will be a key customer of this compute.
S3 Tables: Mind the Iceberg?

The market for commodity data lakes is facing disruption by open source software and standards for lakehouse formats like Apache Iceberg.
Positioning here is frantic: Fierce Snowflake rival Databricks agreed to buy Tabular, a company founded by Apache Iceberg’s creators, in June 2024.
(That brought together the creators of the two leading FOSS lakehouse formats – the other being Databricks’/the Linux Foundation’s Delta Lake.)
Snowflake took its own “Iceberg Tables” GA in June 2024, quoting customers like Booking.com’s Chief Data Officer as appreciating the ability to link existing open source Iceberg-based data lakes and Snowflake – which lets the latter be accessed directly from Snowflake via an Iceberg catalogue integration, using its security, governance and sharing controls.
See also: Amazon EKS gets “Two of the biggest features we’ve ever built”
AWS is now in on the action. It released its new Amazon S3 Tables, which it described as the "first cloud object store with built-in Apache Iceberg support" featuring a new S3 bucket type that is purpose-built to store tabular data. Handy to those who use Iceberg tables exclusively in the AWS ecosystem, perhaps of less interest to those who don't?
Apache Iceberg expert Alex Merced of Dremio told The Stack: "I look forward to exploring how this feature interfaces with AWS Glue and other Iceberg catalogs like Apache Polaris and Nessie to enable maximum portability of these tables across tools. Major platforms like AWS, GCP, Snowflake and Dremio have added features to allow Iceberg to be a first class citizen with with table management, reading and writing.
He added: "Iceberg adoption doesn’t stop there as some platforms are taking more Incremental steps to Iceberg, e.g. Azure has added an Xtable based translation mechanism to translate Iceberg table metadata into Delta for reading within Fabric. Looking forward to seeing all the cloud providers adding full read/write first class support for Apache Iceberg."
DSQL
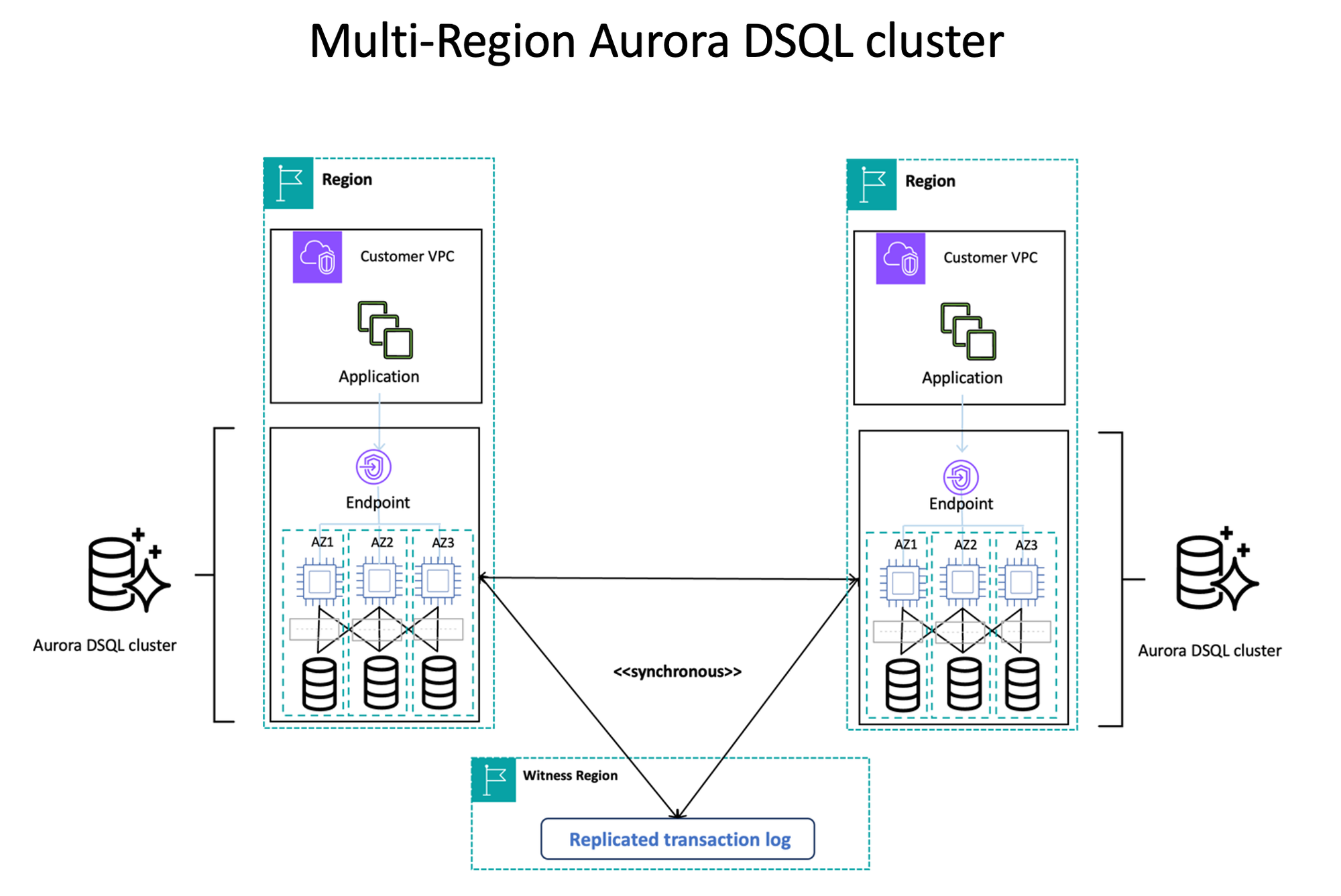
Also a talking point: Amazon Aurora DSQL, a new serverless, distributed SQL database that AWS said provides effectively unlimited horizontal scaling; critically, with independent scaling of reads, writes, compute, and storage.
"Developers can quickly create new clusters with a single API call, and begin using a PostgreSQL-compatible database within minutes.
It supports many common PostgreSQL drivers and tools, as well as core relational features like ACID transactions, SQL queries, secondary indexes, joins, inserts, and updates" said AWS on December 3.
Truly the single most exciting launch I've seen from AWS in a while – Datadog's AJ Stuyvenberg
Dull name, potentially impactful, although not everybody was as impressed. Ed Huang, CTO of Pingcap, a database provider, posted on X: "The architecture is probably a homemade pg-compatible protocol layer + distributed kv (or just a rocksdb instance), as evidenced by the fact that many of the original pg features (JSON, SERIAL) are not supported. PG compatibility is just a gimmick; drop-in replacement is nearly impossible.
"The txn log layer runs a multi-paxos stream (or other RSM algorithm) to support distributed consensus on multiple writers, uses GPS clock + commit wait (like TrueTime) to resolve conflict,There is no evidence DSQL has multiple RSM replication groups. The [quoted] 4x improvement in benchmark over [Google] Spanner came from OCC, which I don't think is a fair test, I constructed my own high-conflict benchmark program, which unsurprisingly performs poorly – Ed Huang, Pingcap.
DSQL automatically scales to meet workload demands without database sharding or instance upgrades; is PostgreSQL compatible; and currently available in preview in the US East and West regions said AWS.







{kind=link}