
Amazon Web Services has promised to build and release a “new support system architecture that actively runs across multiple AWS regions” amid increasingly excoriating criticism of its failure to communicate promptly and accurately during AWS outages – including an incident on December 7, 2021, that locked millions of users out of their consoles and affected numerous services, including its ubiquitous cloud compute offering EC2.
The decision came after the cloud provider (whose customers include Adobe, McDonalds, NASA, Netflix, Unilever and hundreds of thousands of other large enterprises globally) admitted on December 10 that during its most recent outage “networking congestion impaired our Service Health Dashboard tooling from appropriately failing over to our standby region” – it was unable as a result to create support cases for seven hours.
That happened because the issues on December 7 stemmed from a failure on AWS’s internal network. This underpins “foundational services including monitoring, internal DNS, authorization services, and parts of the EC2 control plane” as AWS put it in a December 10 write-up. Some of these failed when a “large surge of connection activity overwhelmed the networking devices between the internal network and the main AWS network; these included its support contact center, which, it admitted “also relies on the internal AWS network”.
Follow The Stack on LinkedIn
(This is, arguably, a stunning failure for a provider that has generated $44 billion in revenues for its three 2021 quarters reported to date and which routinely touts resilience as a key benefit of cloud migration.
“We understand that events like this are more impactful and frustrating when information about what’s happening isn’t readily available” AWS said, adding: “Our Support Contact Center also relies on the internal AWS network, so the ability to create support cases was impacted from 7:33 AM until 2:25 PM PST.
The company added at the bottom of its December 10 post-mortem: “We have been working on several enhancements to our Support Services to ensure we can more reliably and quickly communicate with customers during operational issues. We expect to release a new version of our Service Health Dashboard early next year that will make it easier to understand service impact and a new support system architecture that actively runs across multiple AWS regions to ensure we do not have delays in communicating with customers.”
The pledge of a new AWS support architecture comes as customer frustration not just at the inability to create support cases last week, but at the ability of the AWS service health dashboard to stay resolutely "green" long after an incident has happened and only belatedly acknowledge the scale of issues.
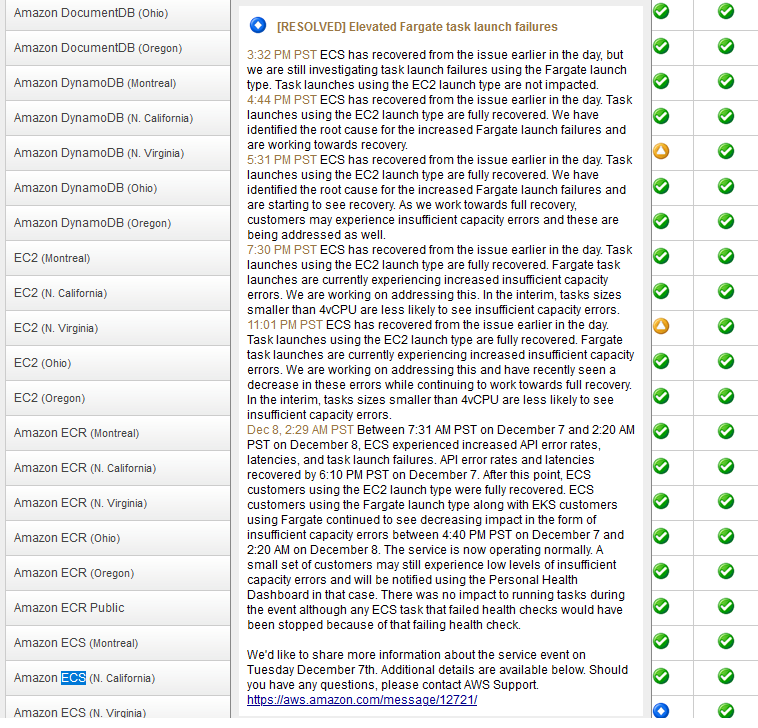
One example: AWS's service history update for its ECS service (which fell over this month as part of the outage detailed above) starts with this update: "ECS has recovered from the issue earlier in the day, but we are still investigating task launch failures using the Fargate launch type. Task launches using the EC2 launch type are not impacted." (There is nothing on the status page about any issue earlier in the day. Customers would have seen "green" service health...)
AWS Service Health Dashboard: So green, such stability
In the wake of a November 2020 outage, AWS had written in its post-incident response for that event that: “We have a back-up means of updating the Service Health Dashboard that has minimal service dependencies.
"While this worked as expected, we encountered several delays during the earlier part of the event in posting to the Service Health Dashboard with this tool, as it is a more manual and less familiar tool for our support operators.” It was not immediately clear if those “minimal” dependencies were also hit this month.
As one frustrated user wrote in the wake of last week’s AWS outage: “It really grinds my gears to hear AWS yammer on about cell-based deploys and minimizing blast radius during Re:Invent and watch the following week as the status page stays green for at least an hour during a regional outage, and then only admit AWS Console problems…” with the author, developer Ryan Scott Brown adding in a blistering blog on AWS’s post-incident write-up: “AWS has made us-east-1 a source of systemic risk for every single AWS customer..”
He pointed to the fact that the issue has been neglected for years, noting that in the wake of a 2017 AWS outage, the company wrote “We were unable to update the individual services’ status on the AWS Service Health Dashboard (SHD) because of a dependency the SHD administration console has on Amazon S3. ... We will do everything we can to learn from this event and use it to improve our availability even further.”
As Brown added: “As a customer, it feels like AWS is prioritizing adding features over serving existing systems… Imagine a new customer starting their AWS account after watching Re:Invent talks with titles like:
- Beyond five 9s: Lessons from our highest available data planes
- How to scale beyond limits with cell-based architectures
- Reliable scalability: How Amazon.com scales in the cloud
- Montioring Production Services at Amazon
- Hands-off: Automating continuous delivery pipelines at Amazon - AWS re:Invent 2020
“They would expect, whenever there is a problem in AWS, for it to be limited in blast radius…”
As AWS's "principal operations fairy" Giorgio Bonfiglio, responded in a Twitter discussion on the event: “After the Kinesis event last year we decided to completely rearchitect the way we do SHD/PHD (Service Health Dashboard/Personal Health Dashboard) and another trail of NDA only updates). Unfortunately this new event happened before some complex action items could complete…
He added: “Although the current SHD can scale in terms of traffic, it doesn't scale in terms of content and mechanism — but things are about to change… Externalising the SHD is a complex topic due to dependencies.”
To Brown – and no doubt others – the wishlist was simple: "A Personal Health Dashboard that wasn't based in us-east-1; A public status page hosted on another provider; An SLA for the status page that includes the time between issue discovery and status page update; Updates as issues happen; Using the red "Service Disruption" icon when more than 50% of a service is impacted; Reducing the blast radius of us-east-1 for other services."
Users will have to wait for an early 2022 AWS outage to see if the promised changes are an improvement.








{kind=link}