Business

Apple researchers have devised a new way of generating data for Large Language Model (LLM) training that involves "rephrasing the web".
The Silicon Valley giant warned that LLMs are often "trained on massive scrapes of the web," which contain noise, unstructured data, or simply badly written content that can wreck model output.
Although synthetic data can be more coherent, it is often "computationally expensive and operationally challenging" to create it using an LLM - as well as running the risk of “knowledge bias” because data is only generated on tasks that engineers "want to perform well on."
Data curation can help filter out unstructured or badly phrased data, thus helping models provide more effective answers.
However, whilst LLM pre-training is often open-sourced, many of the most effective curation techniques are kept behind closed doors and therefore remain unknown to the wider AI community.
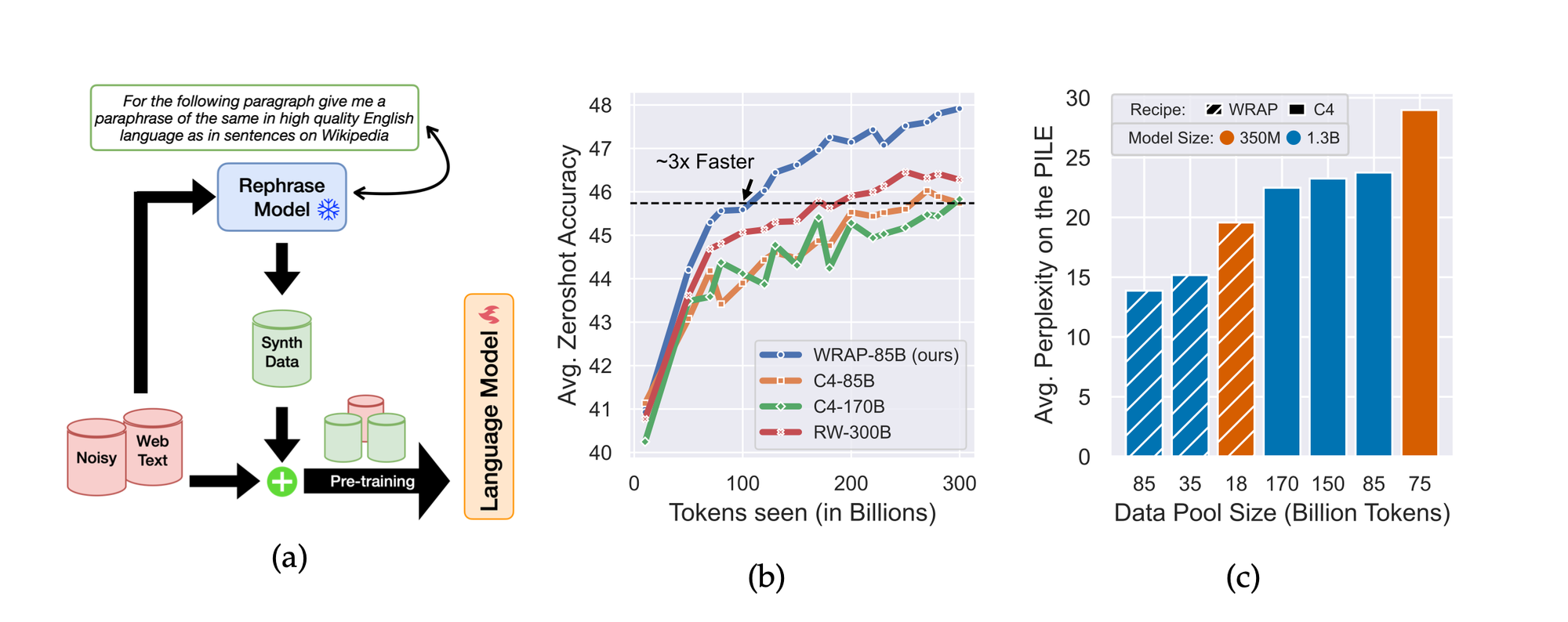
To get around these problems, a team from Apple and Carnegie Mellon University proposed a framework called Web Rephrase Augmented Pre-training (WRAP), which speeds up training as well as driving both compute and data-usage efficiencies.
Instead of generating purely synthetic data, it essentially rewrites content sourced from the web to be more useful for training.
In a pre-print paper, Apple wrote: "Large language models are trained on massive scrapes of the web, which are often unstructured, noisy, and poorly phrased.
"Current scaling laws show that learning from such data requires an abundance of both compute and data, which grows with the size of the model being trained. This is infeasible both because of the large computing costs and duration associated with pre-training and the impending scarcity of high-quality data on the web."
WRAP uses an off-the-shelf instruction-tuned model that can be prompted to paraphrase documents from the Internet in a specific style, such as “like Wikipedia” or “question-answer format.”
When used on a dataset called C4, which is as "naturally noisy" as the plastic explosive that shares its name, pre-training took place roughly three times as quickly.
Furthermore, using WRAP improved perplexity (a measure of how well AI can predict the next word) by more than 10% on average and improved zero-shot question-answer accuracy across 13 tasks by more than 2%.
"Our gains are attributed to the fact that re-phrased synthetic data has higher utility than just real data because it (i) incorporates style diversity that closely reflects downstream evaluation style, and (ii) has higher ‘quality’ than web-scraped data," the researchers added.
It's not all good news. Apple's team also warned that training models on data generated by other LLMs can cause issues with "diversity". In other words, when LLMs are fed the generic pap spat out by other models, they produce even more generic pap.
"Using language models for AI-assisted writing tends to reduce content diversity, particularly when using instruction-tuned models," the team added. "While we used the paradigm of rephrasing specifically to mitigate the issues pertaining to the diversity of novel content generation, it remains for future work to assess the presence (or lack of) and impact of content diversity in paraphrase models."