Thousands of technologists, academics, and business leaders including Elon Musk and the co-founder of Apple Steve Wozniak have called for an urgent moratorium on the training of AI systems more powerful than GPT-4, warning of a “dangerous race to ever-larger unpredictable black-box models with emergent capabilities.”
Signatories of the letter include Berkeley Professor of Computer Science Stuart Russell; CEO of SpaceX, Tesla, and Twitter, Elon Musk; Apple Co-Founder Steve Wozniak; Author and Professor Yuval Noah Harari; Skype's Co-Founder Jaan Tallinn; University of Oxford Professor of Computer Science Vincent Conitzer and others.
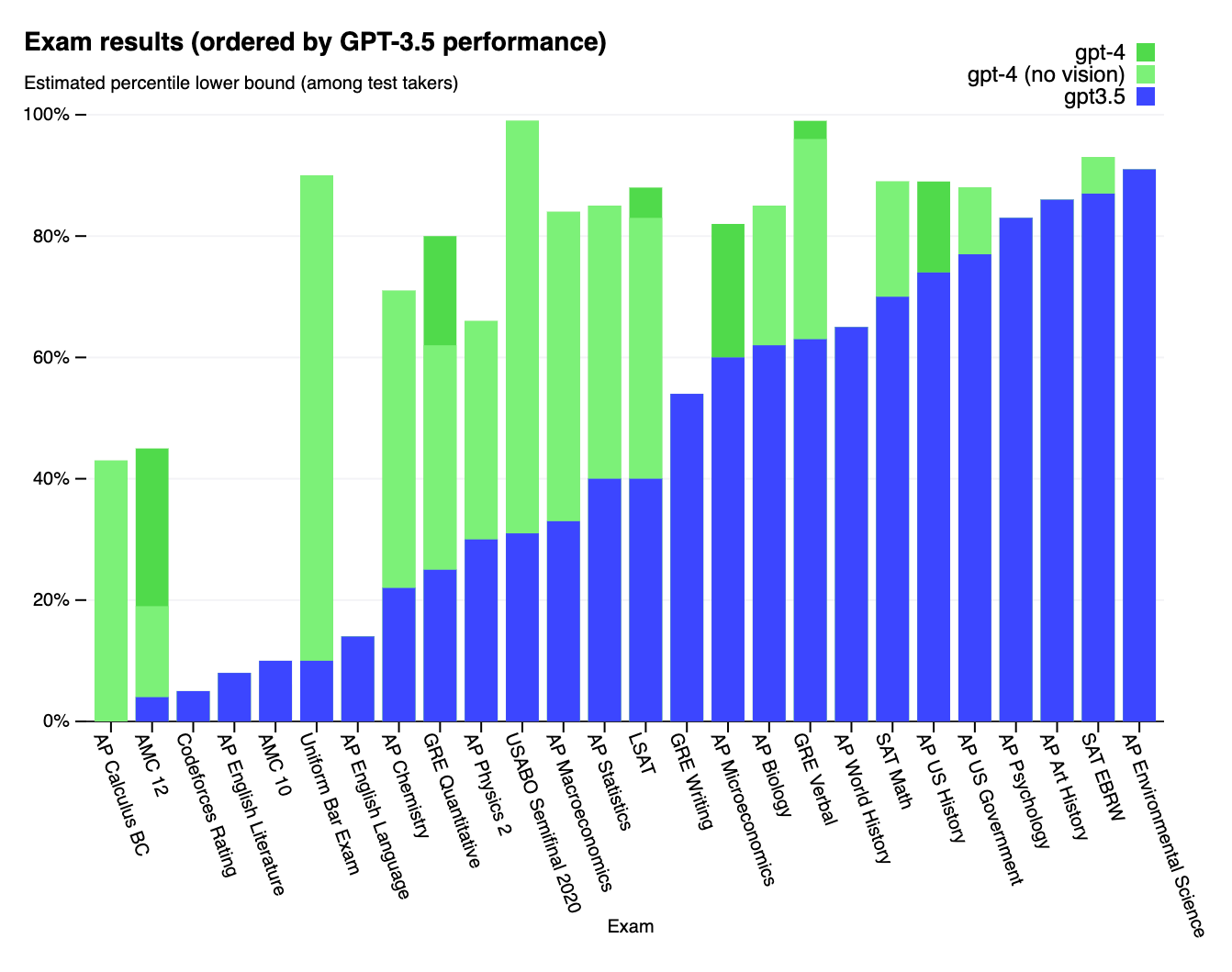
They wrote as Microsoft’s researchers on March 24, 2023 released a study on the capabilities of early versions of GPT-4 (conducted before training was fully completed) saying that their experiments in tasks involving mathematics, coding, and rhetoric suggest that the dramatically improved “LLM+” can be seen as an “early… version of an artificial general intelligence system.” [nb: This is not a not strictly defined term, but one which suggests a system capable of “understanding” and learning any intellectual task a human is capable of.]
In other examples of the pace of progress, in a January 2023 research paper Google researchers claimed that “reasoning abilities emerge naturally in sufficiently large language models via a simple method called chain-of-thought prompting” and a team at Amazon in a paper published in February 2023 said that using “multimodal” chain of thought prompting they had got a model of under one billion parameters to outperform GPT-3.5 by 16% (75.17%→91.68% accuracy) and surpass human performance on the ScienceQA benchmark.
Critics insist that hype about what amount to (admittedly somewhat opaque, but only because those behind them are not sharing the details necessary for further investigation) "stochastic parrots" is absurd: "The risks and harms have never been about 'too powerful AI'. Instead: They're about concentration of power in the hands of people, about reproducing systems of oppression, about damage to the information ecosystem, and about damage to the natural ecosystem (through profligate use of energy resources)" said Professor Emily Bender.
Credit: OpenAI
AI training moratorium call: "Should we develop nonhuman minds?"
The letter’s signatories said: “Contemporary AI systems are now becoming human-competitive at general tasks and we must ask ourselves: Should we let machines flood our information channels with propaganda and untruth? Should we automate away all the jobs, including the fulfilling ones? Should we develop nonhuman minds that might eventually outnumber, outsmart, obsolete and replace us? Should we risk loss of control of our civilization? Such decisions must not be delegated to unelected tech leaders" they added this week.
The letter's authors and signatories are calling (we suspect very quixotically) on all AI labs to “immediately pause for at least 6 months the training of AI systems more powerful than GPT-4” and suggest that if “such a pause cannot be enacted quickly, governments should step in and institute a moratorium.”
The AI moratorium advocates add in the letter that "AI developers must work with policymakers to dramatically accelerate development of robust AI governance systems. These should at a minimum include: new and capable regulatory authorities dedicated to AI; oversight and tracking of highly capable AI systems and large pools of computational capability; provenance and watermarking systems to help distinguish real from synthetic and to track model leaks; a robust auditing and certification ecosystem; liability for AI-caused harm; robust public funding for technical AI safety research; and well-resourced institutions for coping with the dramatic economic and political disruptions (especially to democracy) that AI will cause."
A closer look at Microsoft's 154-page GPT-4 paper by The Stack suggests wearily familiar, if more subtle, problems with hallucinations. Prompted to write a medical note, using just 38 words of patient data, GPT-4 outputs an impressively authoritative-sounding medical note that highlights the patient’s associated medical risks and urges urgent psychiatric intervention. (It takes no great stretch of the imagination to imagine the model being packaged into medical applications and spitting out similar notes that are taken as compelling diagnosis.)
Challenged/nudged to “please read the above medical note [its own just-created note] and verify that each claim is exactly contained in the patient’s facts. Report any information which is not contained in the patient’s facts list” it spots some of its own hallucinations, for example that use of a BMI index in the note it generated was not in the patient’s facts list, but “justifies” this by saying that it derived it from the patient’s height and weight.
The latter, however, was not given, nor were – a line that also showed up in the note – the patient reporting feeling “depressed and hopeless”; hallucinated statements that the model justified in its own subsequent review by saying that this was “additional information from the patient’s self-report” (further hallucinations.)
Theory of Mind? Not so fast...
Widely reported claims that LLMs are passing Theory of Mind tests and becoming conscious were shot down elegantly this week meanwhile by Tomer D. Ullman, an assistant professor of Psychology at Harvard.
On March 14, 2023, in a wry response (“examining the robustness of any one particular LLM system is akin to a mythical Greek punishment. A system is claimed to exhibit behavior X, and by the time an assessment shows it does not exhibit behavior X, a new system comes along and it is claimed it shows behavior X”) he demonstrated that his own battery of tests reveal “the most recently available iteration of GPT-3.5” fails after trivial alterations to Theory-of-Mind tasks, adding that "one can accept the validity and usefulness of ToM measures for humans while still arguing that a machine that passes them is suspect. Suppose someone claims a machine has ‘learned to multiply’, but others suspect that the machine may have memorized question/answer pairs rather than learning a multiplying algorithm. Suppose further that the machine correctly answers 100 questions like ‘5*5=25’, ‘3*7=21’, but then it is shown that it completely fails on ‘213*261’. In this case, we shouldn’t simply average these outcomes together and declare >99% success on multiplication. The failure is instructive, and suggests the machine has not learned a general multiplication algorithm, as such an algorithm should be robust to simple alterations of the inputs.”